Apr 06, 2020
Git 基础学习总结
基本概念
一般来说,开始使用git的场景分为从远程服务器克隆已存在的项目和开始新项目,初始化仓库。前者直接使用git clone XXXXX(远程仓库地址)就可以将远端的仓库完整的拷贝到本地。
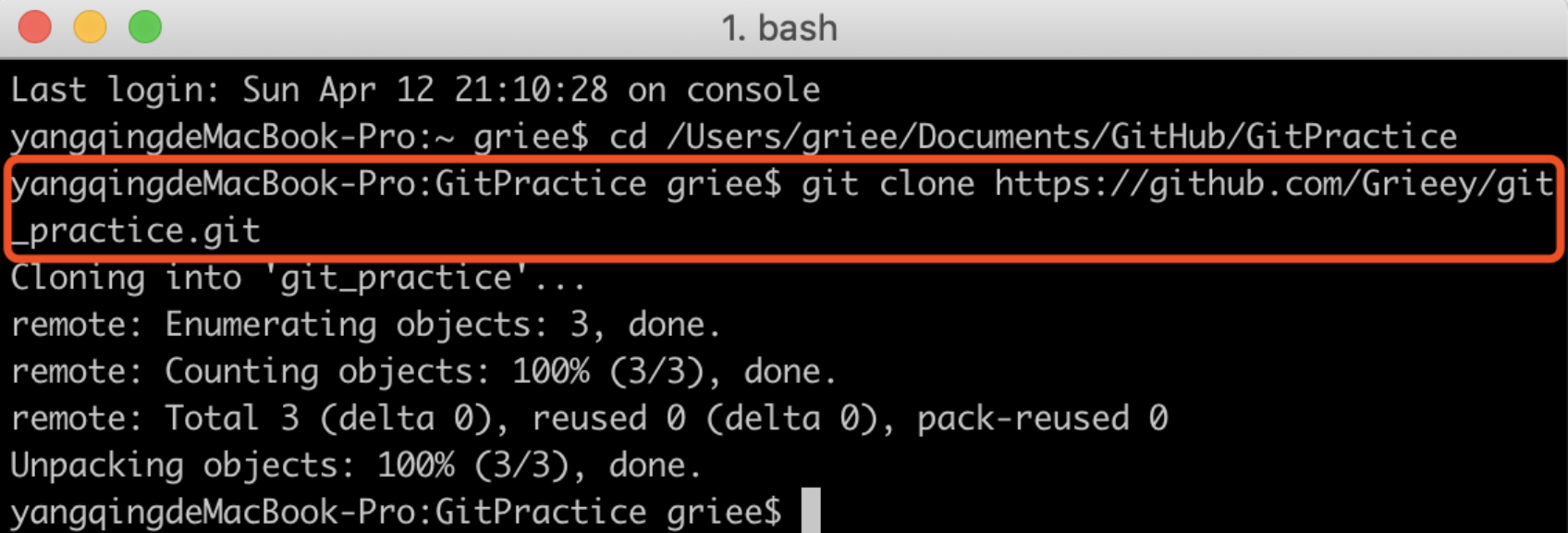
不过从头开始初始化一个本地仓库,更容易去理解git 的工作流程。命令git init可以将一个文件目录初始化为一个仓库, git会相应的生成一个.git的文件夹,这个文件夹就是 本地仓库(Local Repository),这个文件夹中就会保存该目录中之后所有文件的改动记录,而这个目录在git中就被称为工作区(Working Directory)。
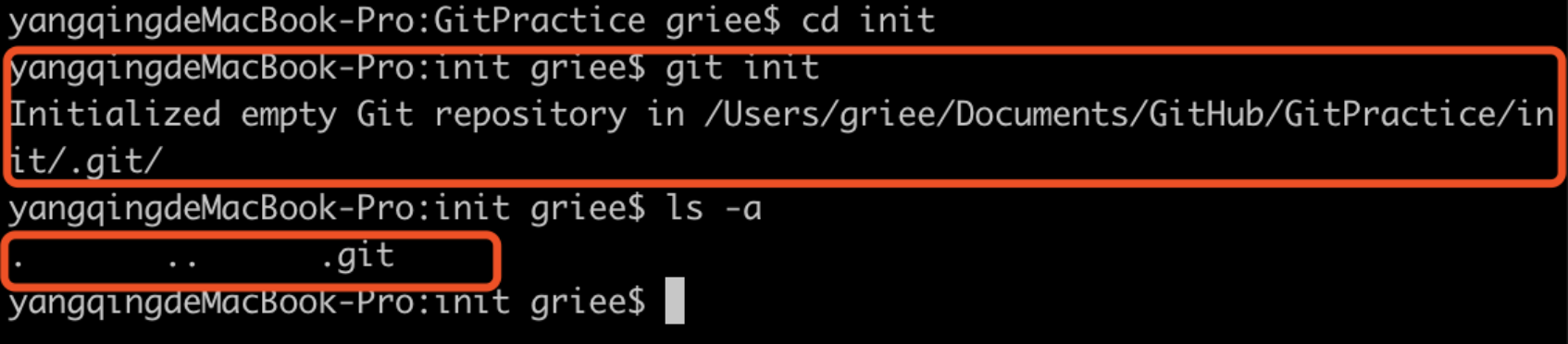
除了工作区以外,git中还有暂存区。(注意:这里我是新建了一个文件夹,进行的初始化操作,如果新建的文件夹是刚刚克隆的git目录中,在已存在的仓库中再次git init一个仓库会不会有什么问题,答案是并不会,git中使用的是目录管理而不是设备管理,一个仓库只会对应的管理其对应的目录,不会相互影响)
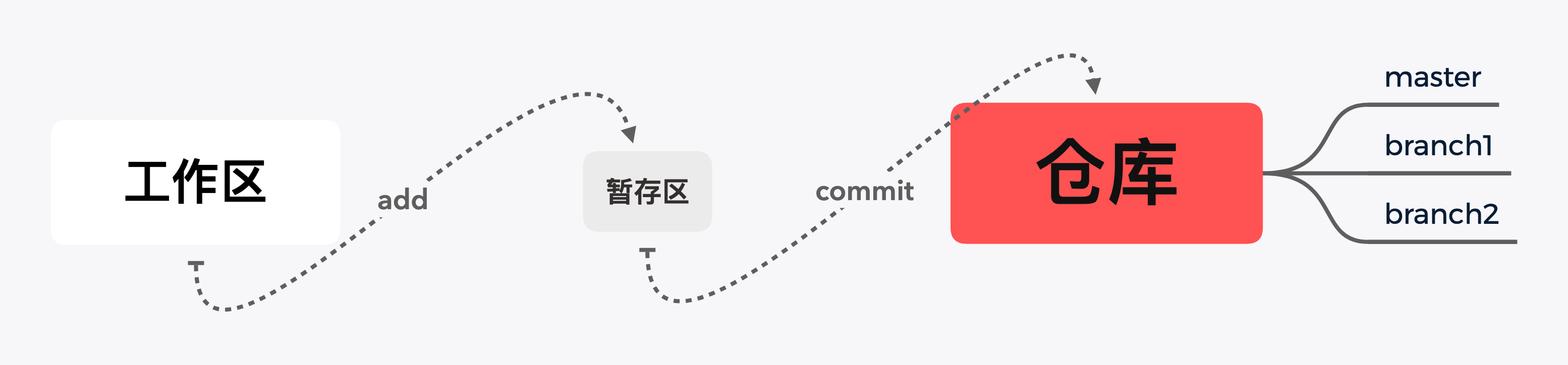
如上图,是git的一个基本的工作流程:当我们在工作区域中修改了某个文件的文件内容时,git会自动检测到这种改动并进行了标记,然后需要我们手动的将这些改动添加(使用命令 git add)到暂存区中,这样我们所修改的东西就会被git记录下来,而没有添加到暂存区的改动在进行各种git命令时可能会丢失。如果我们确定了暂存区中的内容是这样的修改,就可以将暂存区的改动记录进行提交,那么这次修改的内容就会从暂存区迁移到仓库中,并在仓库中生成一个提交记录–commit。整个仓库中,所有的改动记录就是有一个一个的commit串行所构成的。
以下就是文件在不同的区域的一个时序图:
1 | sequenceDiagram |
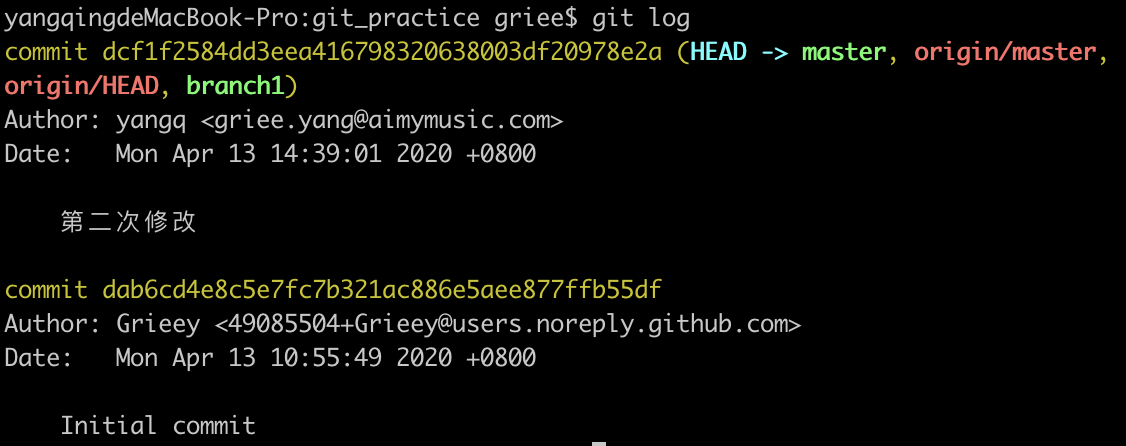
回到我们刚刚克隆的仓库中,使用命令git log可以查看当前仓库的一些日志。
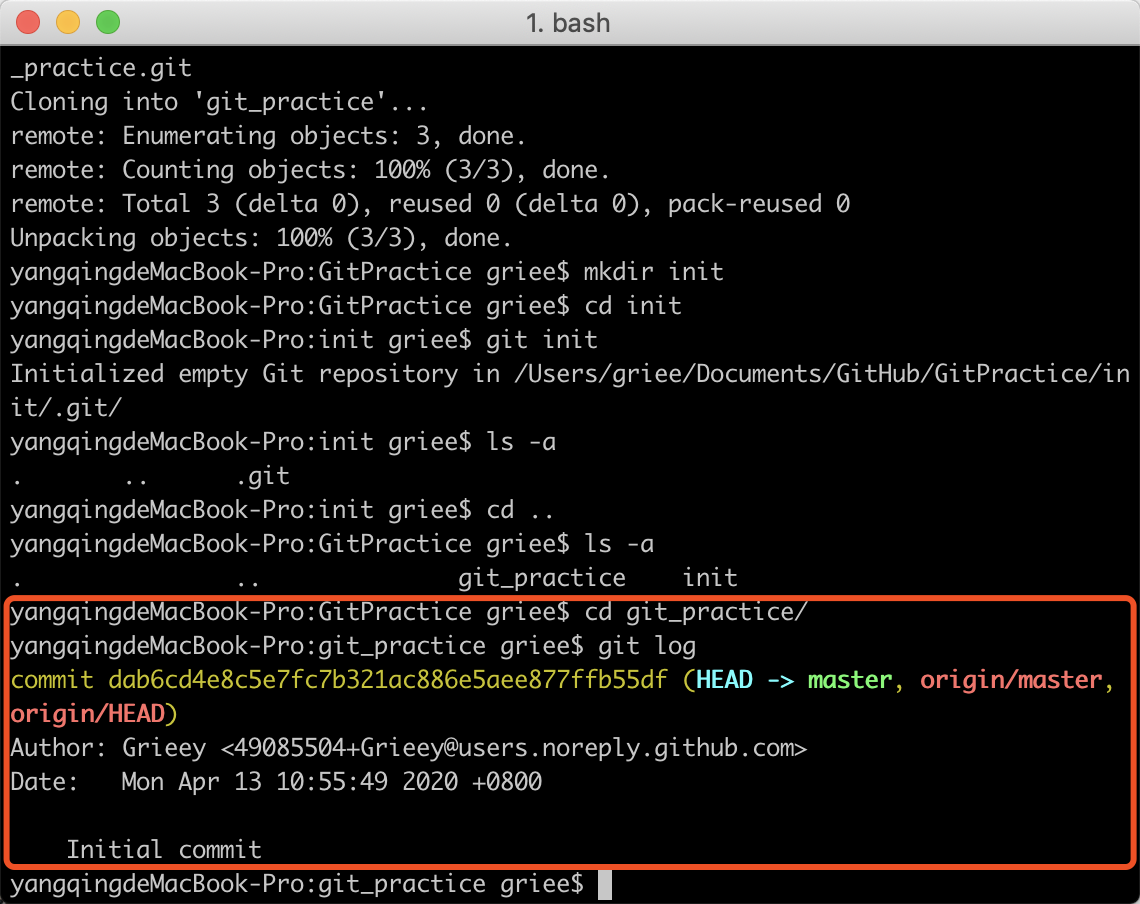
分析图中出现的数据,就衍生出来 git 中的几个重要的概念:
引用
简单来说,git中的引用就是指向某个commit的快捷方式,我们通过操作引用能够快速的操作到某个具体的commit,可以看到上图中红圈中的内容,记录中显示,远端仓库只有一次commit,该commit的后面跟着一串字符串,这个字符串是根据该commit计算出来的SHA-1值(一种算法计算出来的值,两个 commit 计算出来的值很少能重复),commit将其作为唯一的标识。大多数时候,我们需要操作具体的某个commit时,可以直接使用该值的前几位来代表这个commit,如
1 | git checkout dab6cd |
上面这个命令就会签出dab6cd这个commit。
HEAD
这个引用比较特殊,它指的是指向当前commit的引用,当我们从远端仓库拉取代码时或者checkout新的分支时,HEAD指向会随着我们的操作相应的修改,使得它始终指向的是当前工作区中对应的commit。
master
这个是git在创建时,默认生成的一个分支。大多数工程都将该分支作为主分支使用,在开发时,建立其他分支来开发工作,最后将完善的功能合并到主分支中。上图中的origin/master, origin/HEAD代表的是远程仓库的master分支最新的commit和远程仓库的HEAD指向的commit都是dab6cd,值得一提的是,无论本地的HEAD如何修改,远程仓库中的HEAD永远指向的是master分支。
branch
分支,既然有默认的分支,那也代表我们可以创建其他分支。其实,在整个git仓库中,是由一个个的分支构成,而分支由一个个的commit构成。形象一点说就是git仓库像一颗大树,master分支就是大树成长时的主干,慢慢随着长大,出现了许多的树枝,这些树枝就是我们自己新建的branch,而树枝上的树叶就是一个个commit。
当HEAD指向某个branch时,其实间接的是指向这个branch的某个commit(之所以说是间接的指向,是因为这种情况下的HEAD还是直接指向的branch,而branch指向的是它最新的commit,这样构成了间接的指向。还有直接的指向,就是使用git checkout --detach命令后,HEAD就会由指向branch变成指向commit)。如下所示
1 | graph LR |
git checkout xxx这个命令翻译为 签出,使用该命令签出某个commit时,工作区的内容会替换为该commit,并同时将 HEAD 引用指向该commit,当签出命令为某个分支时,会签出该分支的最新的那个commit
branch的构成是一条从起始commit到该branch最新的commit的一条路径,它所包含的信息就是这条commit链上所有的commit。
基本流程中的操作
完整流程
假设我们已经将文件改动好了,可以使用git status命令来查看当前的一些状态
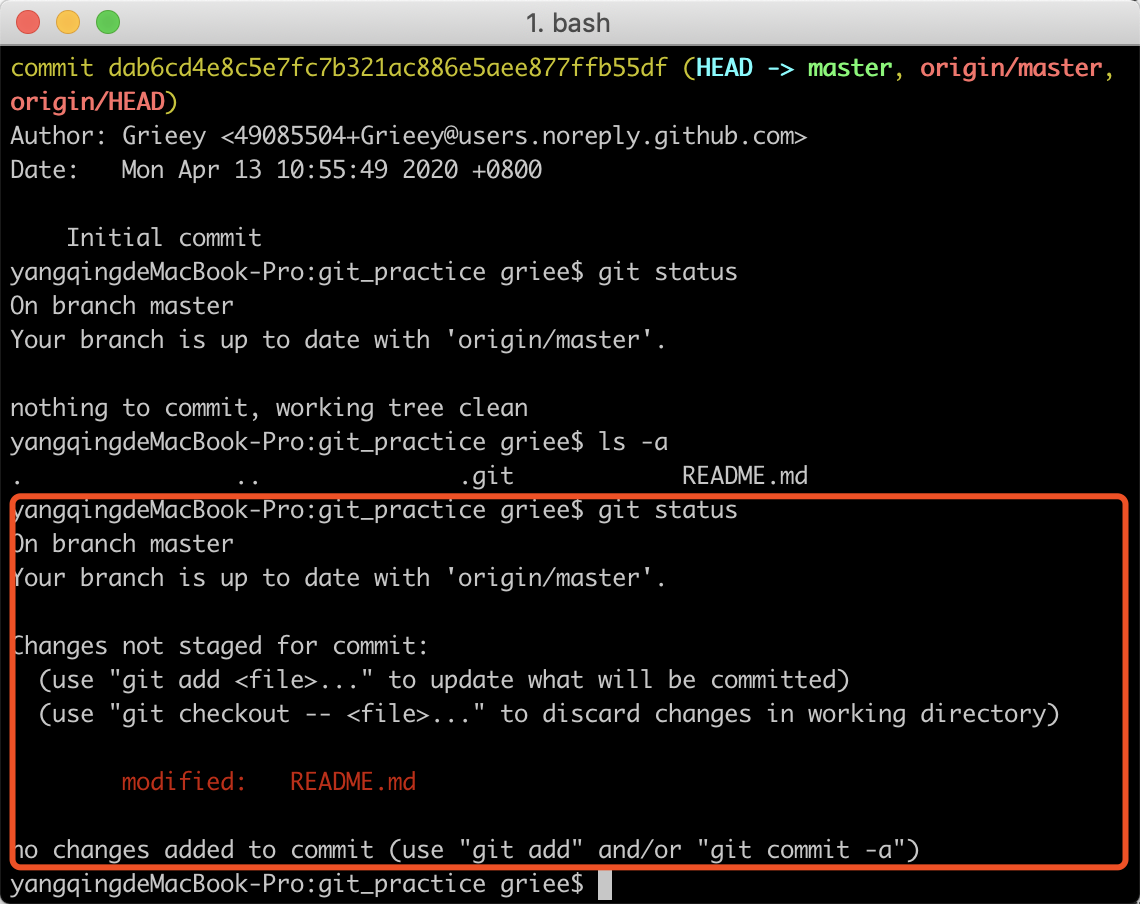
可以看到git对修改的文件进行了标识,显示为红色的 modified,红色的意思是代表这些改动还没有被添加到暂存区中,也就是处于一种被标记了,但是没有被记录的状态。
然后执行git add .,将修改添加到暂存区中,再次查看
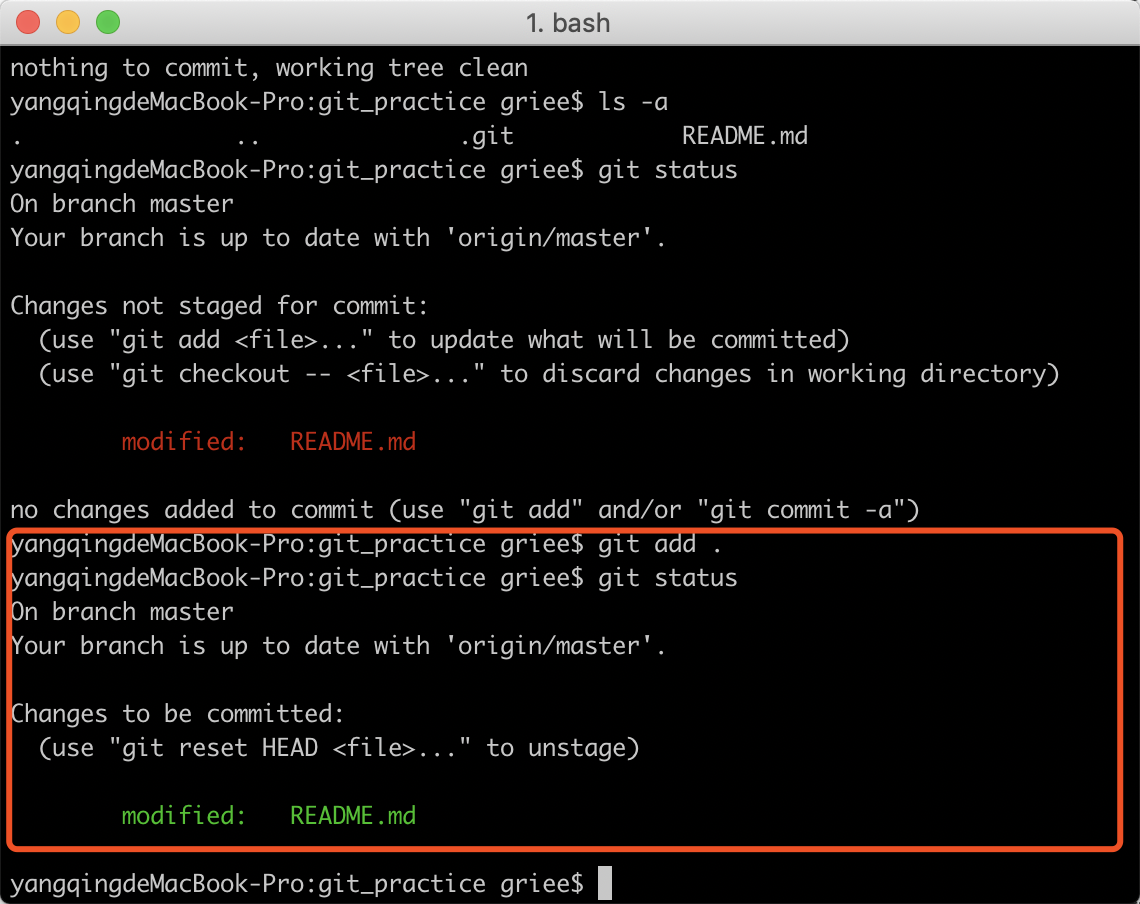
可以看到刚刚的红色变成了绿色,这表示已经添加到了暂存区中。
最后使用git commit -m "本次提交的描述"命令可以将暂存区中的改动记录提交到仓库中
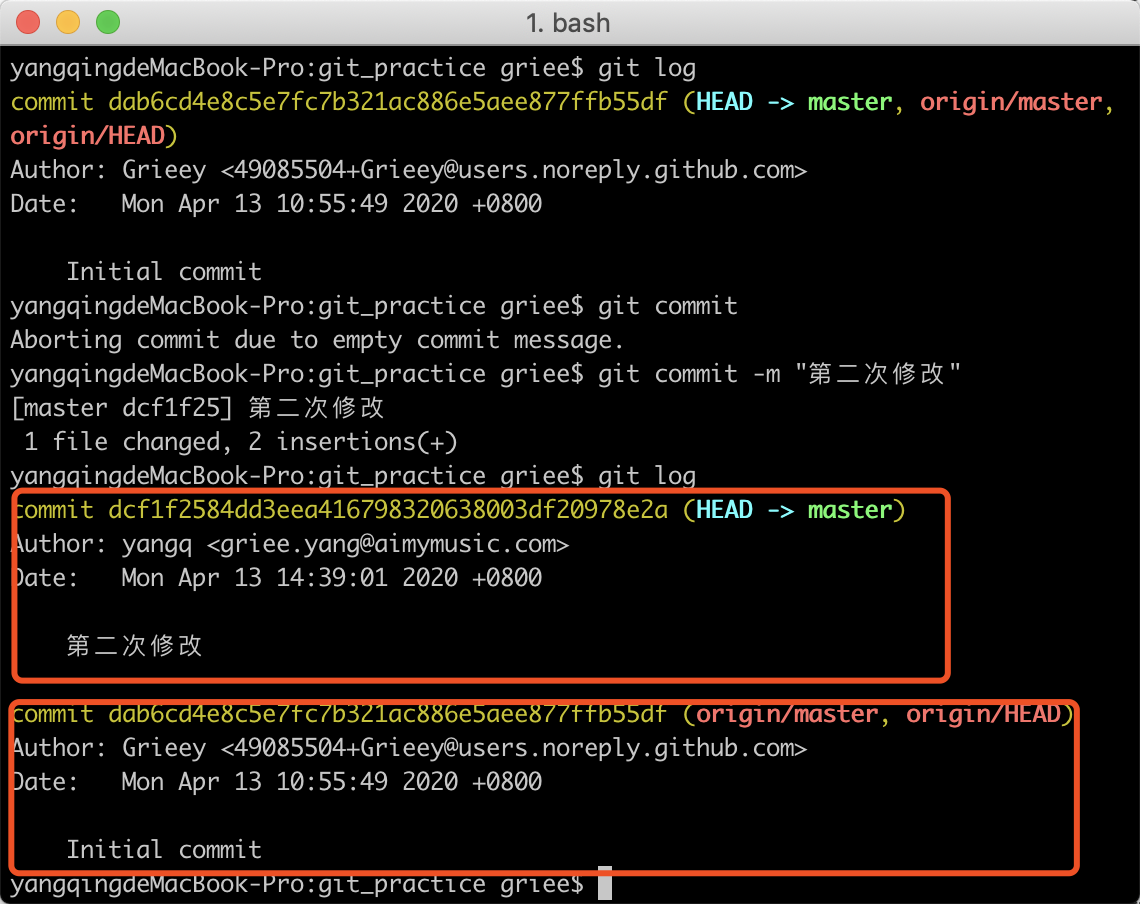
通过上图可以看到,现在仓库中存在两条commit记录,HEAD也指向了刚刚提交的最新的commit,而远端依然指向的是克隆时的commit,因为没有人提交了commit到远端。
现在,可以将刚刚的改动提交到远端,但是正常情况下,我们其实并不知道远端是否有新的改动,所以一个比较保险的做法,先进行一次拉取操作git pull,这样如果远端有人提交了改动,我们就能先拉取合并。再把最后合并和的提交一起推到远端仓库。
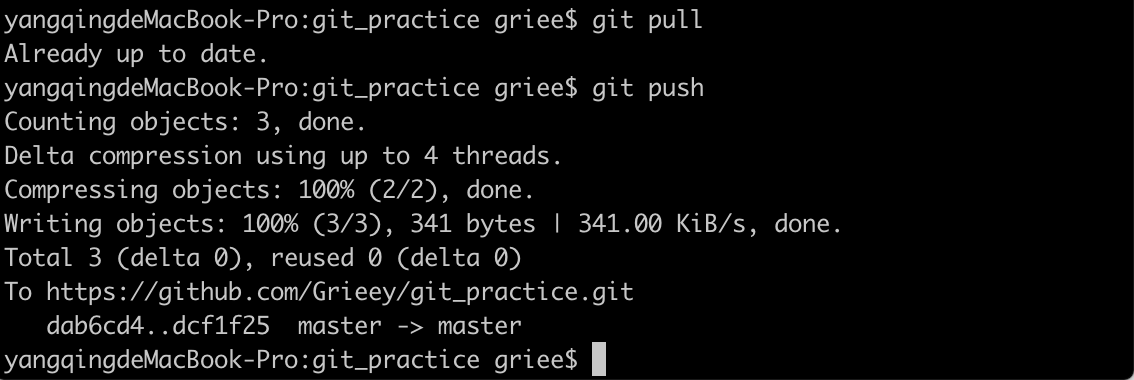
现在再查看下本地的状态,可以看到,远端的HEAD也指向了最新commit
这算是一次比较顺利的工作流程,从本地修改文件,然后提交记录,再推送到远端进行了合并,以方便其他同事拉取你的修改。但是大多数情况下,并不会这么顺利,会产生比较多的冲突。
###关于CLONE
当我们使用git clone的命令时,git 首先是将远程仓库的快照下载到本地。然后根据快照中的分支和commit去下载对应的commit。然后git 会从第一个起点的commit开始,一个一个的应用commit链上的commit到工作区中,直到最新的那个commit被应用上。
关于 ADD
刚刚的流程中使用了add命令,我使用的是git add .后面跟了一个.这个的意思是,全部暂存。如果你不想全部暂存,就需要把.替换成需要暂存的文件名。
我们在工作区中,新增的文件,默认是不会被git所追踪的,也就说文件中任何的改动是不被git检测记录的。需要使用git add命令将文件添加,这样git才会开始追踪,所以新增一个文件时,使用add命令的含义其实有两层,一个将这个文件的新增作为工作区中的一种形式的改动,提交到git仓库中,第二层就是让文件被git所追踪。其他时候,当我们做出一些修改的时候,需要添加到暂存区中,也是使用此命令。
需要注意的一点是,git中所记录的是文件内容的改动,而非文件本身,所以当添加了一次文件的修改后,又修改了相同文件的内容,还需要再添加一次刚刚的修改。如下操作:
1 | 改动了文本的内容 |
关于 PULL
git pull操作其实就做了两件事,先将远端的commits拉取到本地,然后进行一次合并操作
关于 PUSH
刚刚的操作中,使用git push就将master分支上新的commit推到了远端仓库,与远端仓库的master分支进行了合并。这其实是一种粗略的说法,一笔带过了。
git push 会将默认分支的本地提交记录上传到远程分支上进行合并,如果不指定的话,所更新的分支为git config 中的 push.default的值对应的分支,这个值默认为:current 其中的值git config 命令来进行修改, 进而改变 push 时的行为,详情查看git config。如果需要提交记录的分支不是默认的分支,需要在命令中添加几个新的参数
1 | git push origin target_feature |
那么这次的 push 会推向远程分支的target_feature分支
**注意:push 时不会上传 HEAD 的指向,远程分支的 HEAD 永远指向的是 master **
分支相关的操作
分支的创建和删除
- 创建
branch的方式是git branch 名称或git checkout -b 名称(创建后自动切换); - 切换的方式是
git checkout 名称; - 删除的方式是
git branch -d 名称。
分支的合并 Merge
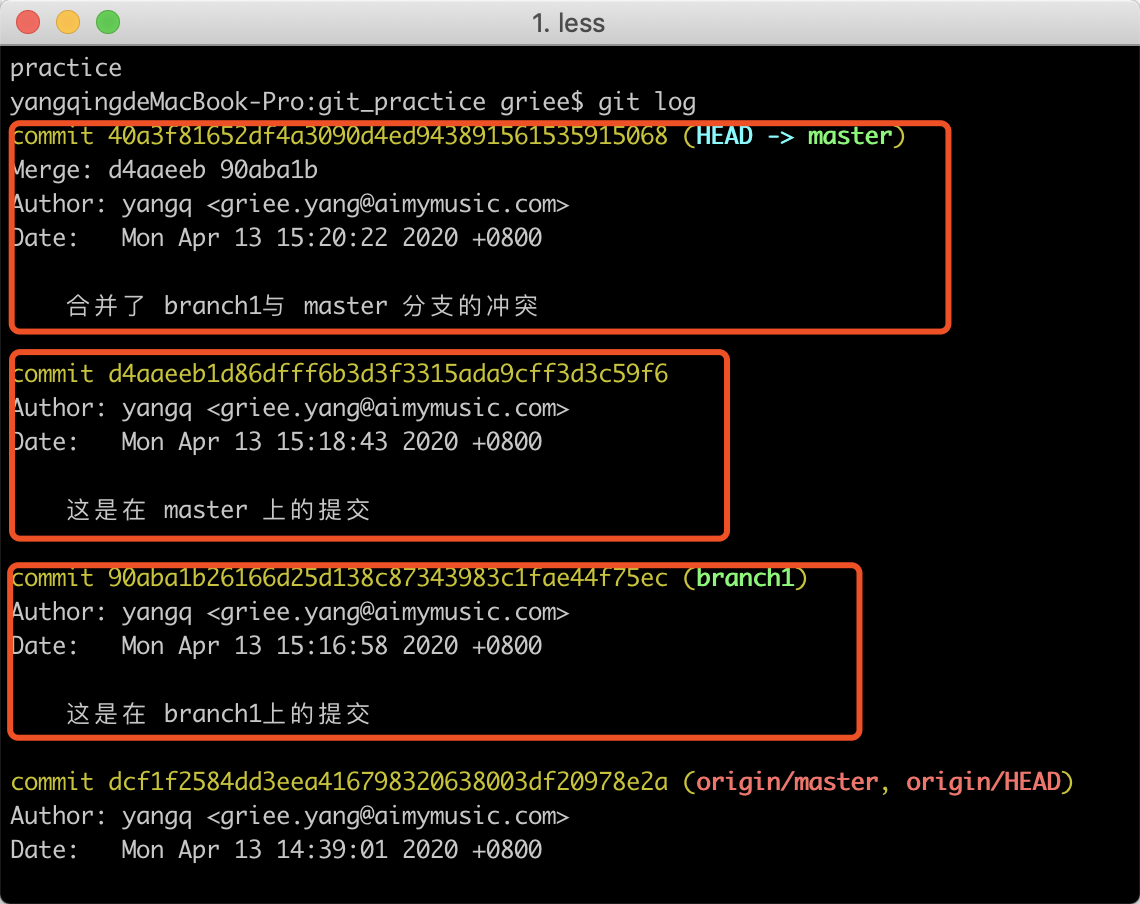
多数情况下,我们需要将不同的分支的代码进行合并,那么就需要使用到git merge命令,该命令具体做的事情是:从目标 commit 和当前 commit (即 HEAD 所指向的 commit)分叉的位置起,把目标 commit 的路径上的所有 commit 的内容一并应用到当前 commit,然后自动生成一个新的 commit。
在合并时,最舒服的状态就是,新的分支的改动是领先于合并的分支的,这时候只需要将新分支的commits直接移过来,就完成了一次合并,在git中被叫做fast-forward。不过大多数时候,还是不那么舒服的。
解决冲突
首先我们需要切换到branch1分支,对README.md文件进行修改。并按照流程进行了提交。
然后切换回master分支,同样的对README.md文件进行了修改,也进行了提交。
那么这个时候,同一文件,在不同的分支上都进行了改动,对于git 而言,可以分为良性情况和恶性情况(git中没有这个定义,只是为了理解)。什么是良性的呢,就是两次改动的地方不一样,比如有5行文本,branch1分支中改下了第4行,而master分支中修改了第3行,这样git就能知道两个分支改的东西不一样,就能自动合并,最后新生成的commit就是第3行和第4行都被修改了。对应来说,恶性的就是两个分支的改动,改了同一处地方,git并不知道哪个分支的改动才是我们想要的,所以最后的决定权交到了我们自己手里,这个时候就需要手动的处理冲突。
在git中,对于这种冲突,会做一些明显的标识如下
1 | >>>>>>> HEAD |
这个很容易理解,上面的内容是HEAD所在的master分支的修改,下面的是branch1分支的修改,我们根据具体的需求进行修改,删除git自动生成的>>>>>和======。这算一次新的改动了,所以需要再次进行add .和commit。
可以看到,这个过程中一共生成了3个commit。
不解决冲突
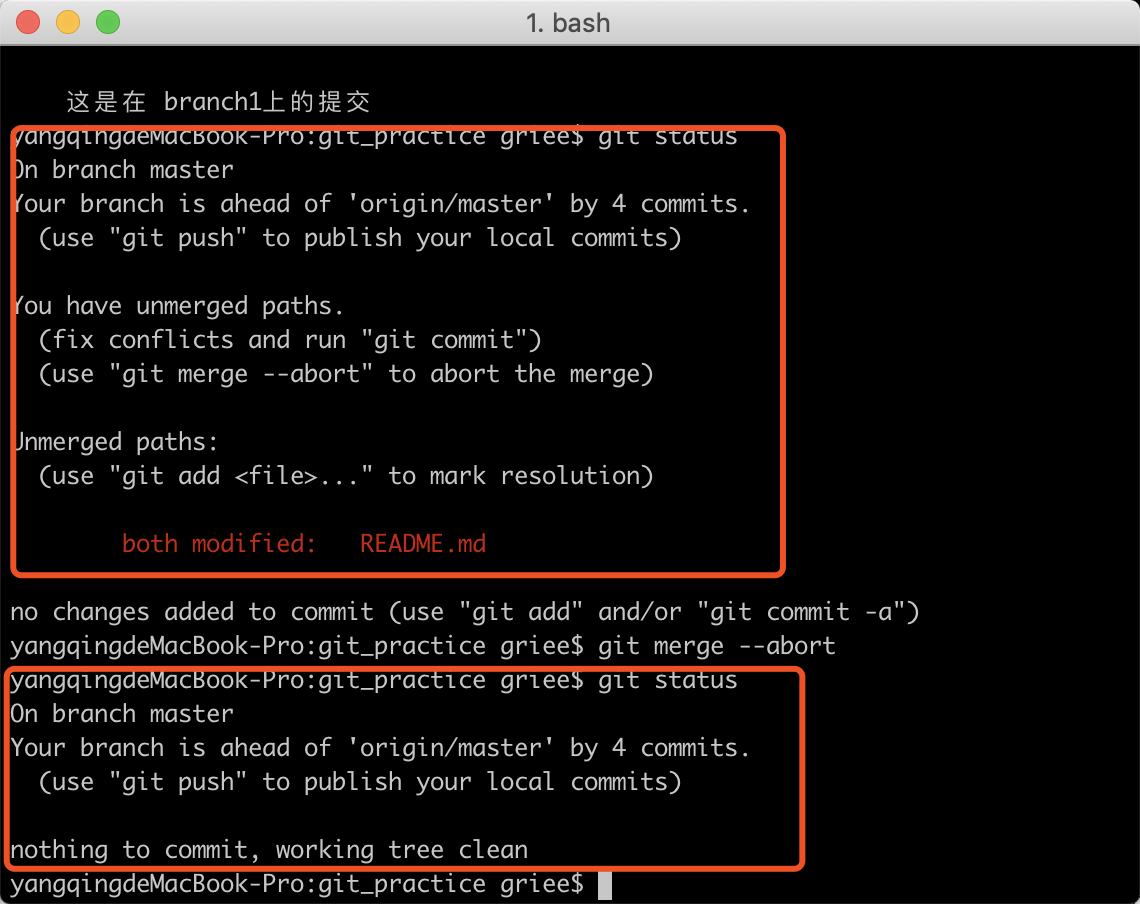
上诉的操作代表正常处理了一次冲突,如果不需要处理,想要放弃。可以使用以下命令
1 | git merge --abort |
之后便回到 merge 前的状态。如图所示,在合并时,产生了冲突both modified: README.md,执行命令后,状态回到了master合并之前。
进阶操作
注意:进阶操作中的命令,请先在自己的 DEMO 中多次练习熟悉后,再在实际的工程中使用,某些命令一旦出错,请千万不要 Push 到远程分支,哪怕丢弃掉本地所有的修改。
在操作本地的 commit 时,需要考虑对远端分支的影响,尤其是多人协同的分支
禁止使用 rebase 命令对任何已经提交到远程分支的 commit 进行操作
仅合并少数几个 commit
在实际工作开发中,会遵循标准的 Git Work flow,对待不同的功能,会切出不同的分支进行 coding,所以,基于什么基准分支切出来的功能分支进行 coding,这是一个很重要的问题。
如果切错了基准分支,你会发现可能最终开发完成之后, merge 不回去了。或者需要将某个分支上的 commit 代码,移植到某个分支上面,就需要使用到 cherry-pick 这个 git 命令了。
这个命令的用法如下,
1 | git cherry-pick -x <commit_id> |
其中-x的参数代表保留原提交者的信息,后面的<commit_id>的写法就是<start-commit-id>…<end-commit-id>这个代表一个从startCommitId到endCommitId的一个左开右闭的区别(startId, endId],如果需要包含startId可以添加一个符号<start-commit-id>^…<end-commit-id>这样就是[startId,endID]的一个闭区间了。
提交的记录可以通过git log --pretty=oneline来查看。
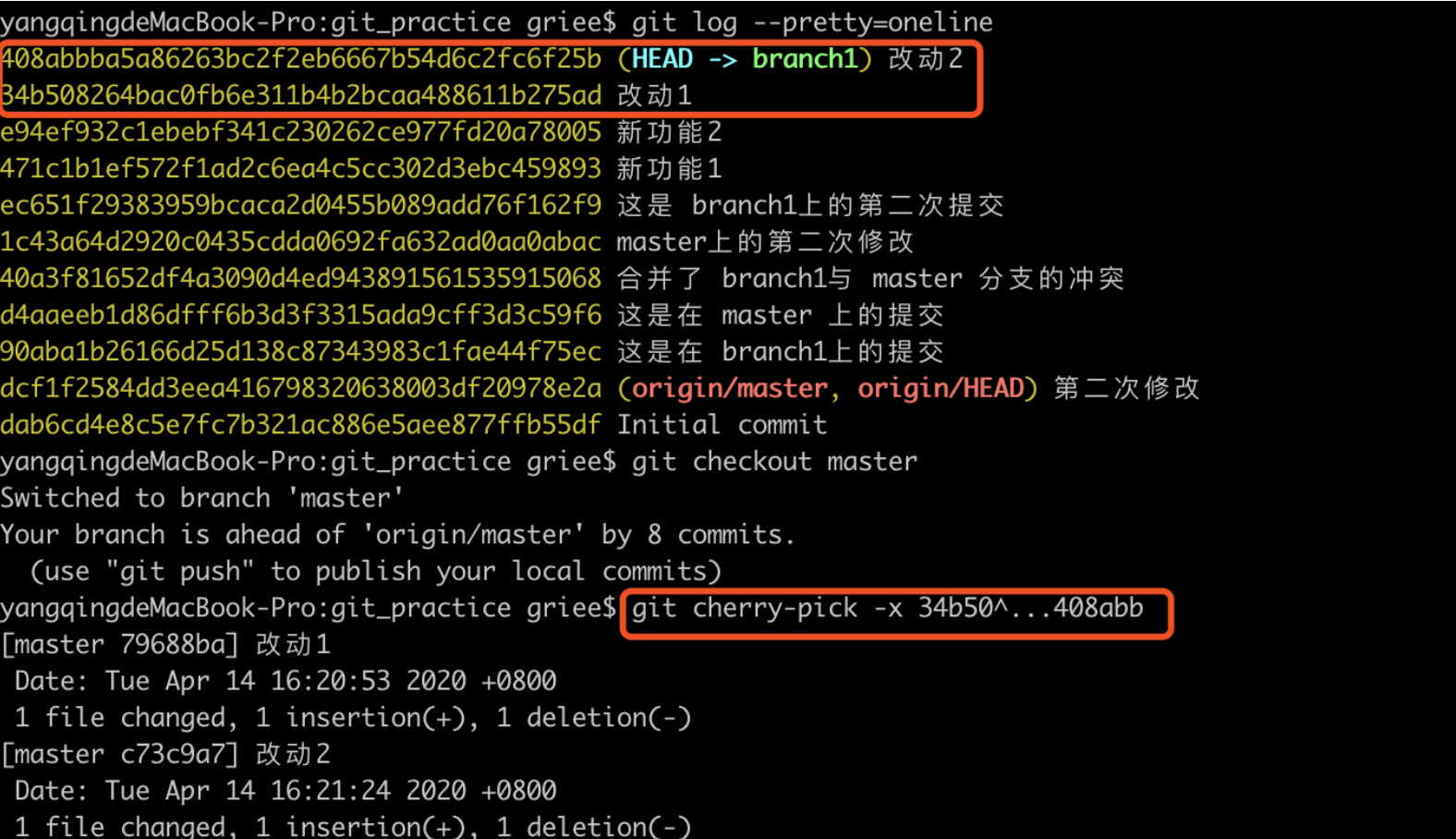
然后查看master分支的commit会发现刚刚合并的已经有了。
合并过程中,如果出现了冲突,就和普通冲突一样,手动的解决,然后添加提交,再执行git cherry-pick --continue就可以继续了,直到合并完成。
rebase 与 merge
rebase的直译是改变基点,其实这个指令的功能也差不多是这个意思。那我们看看这个命令的具体使用及应用场景。
通过上面的命令,可以知道在执行merge操作时,会生成一个新的commit,同时整个历史记录上也会保留合并的痕迹(branch1会与master形成一个回路的形式),这样对代码的历史并不是线性的,看起来不是很直观。
1 | 1-->2-->3-->4-->5-->6 master |
那么使用rebase命令的效果是什么样的呢。
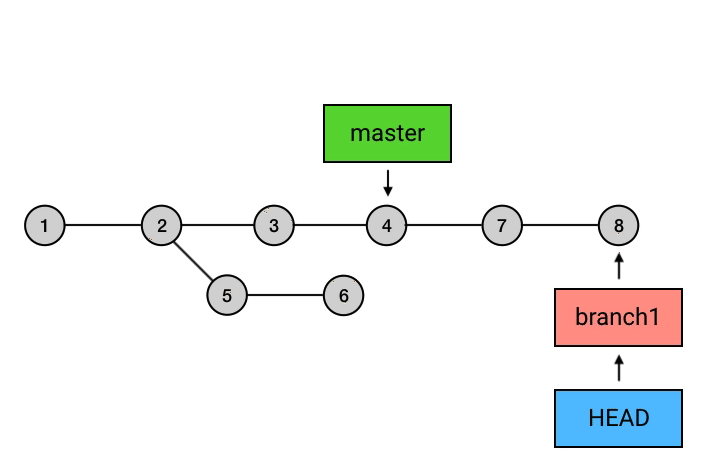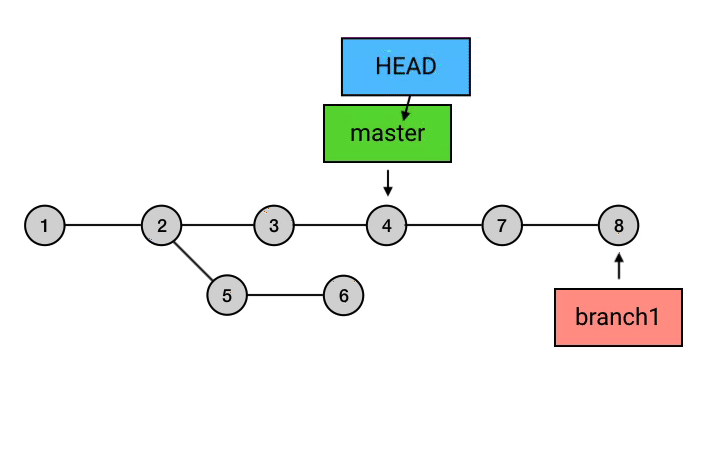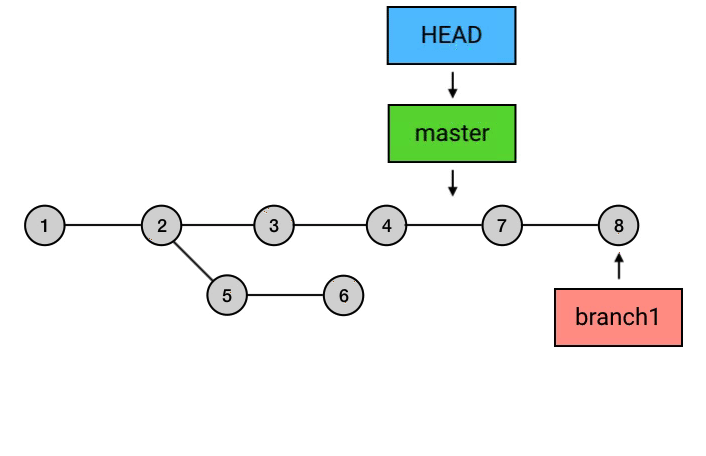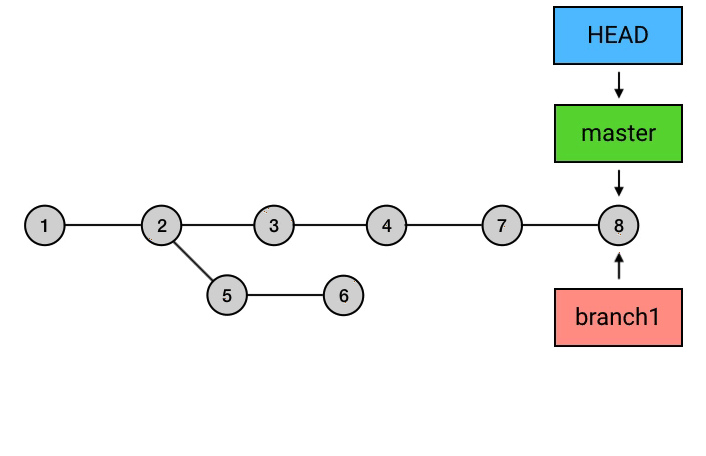
首先,我们需要**切换分支到branch1分支上使用rebase命令 **,这一点需要注意,就是在哪个分支执行这个命令。
1 | git checkout branch1 |
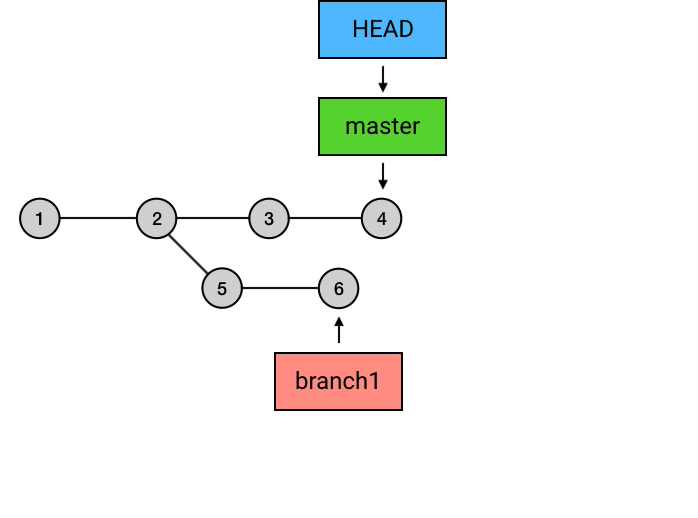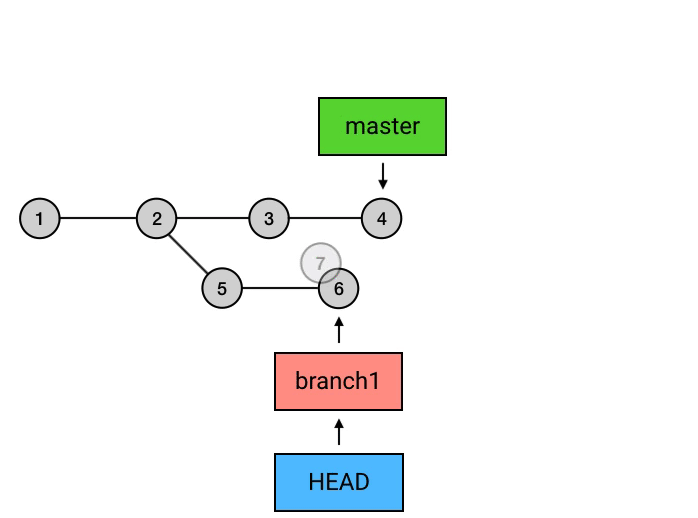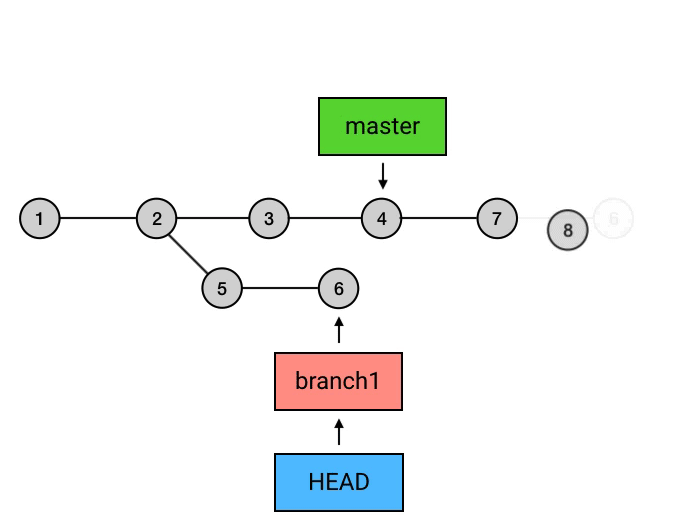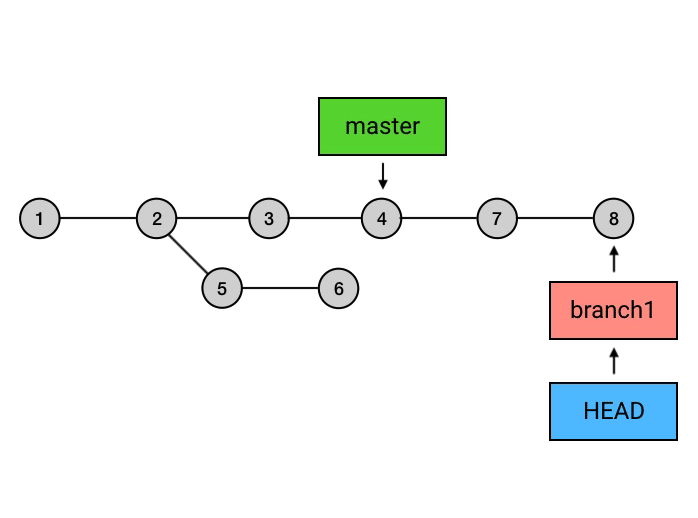
上面的命令执行之后,git所做的事如上图所示,切换分支后,HEAD指向移动到了 branch1分支的最新commit上,然后执行git rebase master,这个命令会将从master分支与branch1交叉开始之后的commits的基点都修改到master分支上,并移动branch1和HEAD的指向,但是需要注意的是,这个操作完成之后,在master上的7、8的commit和之前的5、6仅仅是内容相同,本质上依然属于两个不同的commit。这样操作就完了么?并没有,还需要回到master分支,执行一次merge,因为刚刚的操作结果仅仅是将branch1分支的commit接在了master上,而master的指向依然是之前的commit,所以这里的操作相当于执行了一次fast-forward。
1 | git checkout master |
这样,整个过程才算完成了。这样看起来好像比直接merge的操作要复杂很多,那么它的意义在哪儿呢,这个就得看具体的需求了,关于rebase 和 merge更深入的理解可以参考文章rebase 和 merge 详解。
熟悉了理论后,根据上面的知识点进行一次实际的操作来加深理解。
同样的,现在在master分支和branch1分支上都进行了修改,那么我们现在处于branch1分支中,执行rebase命令。
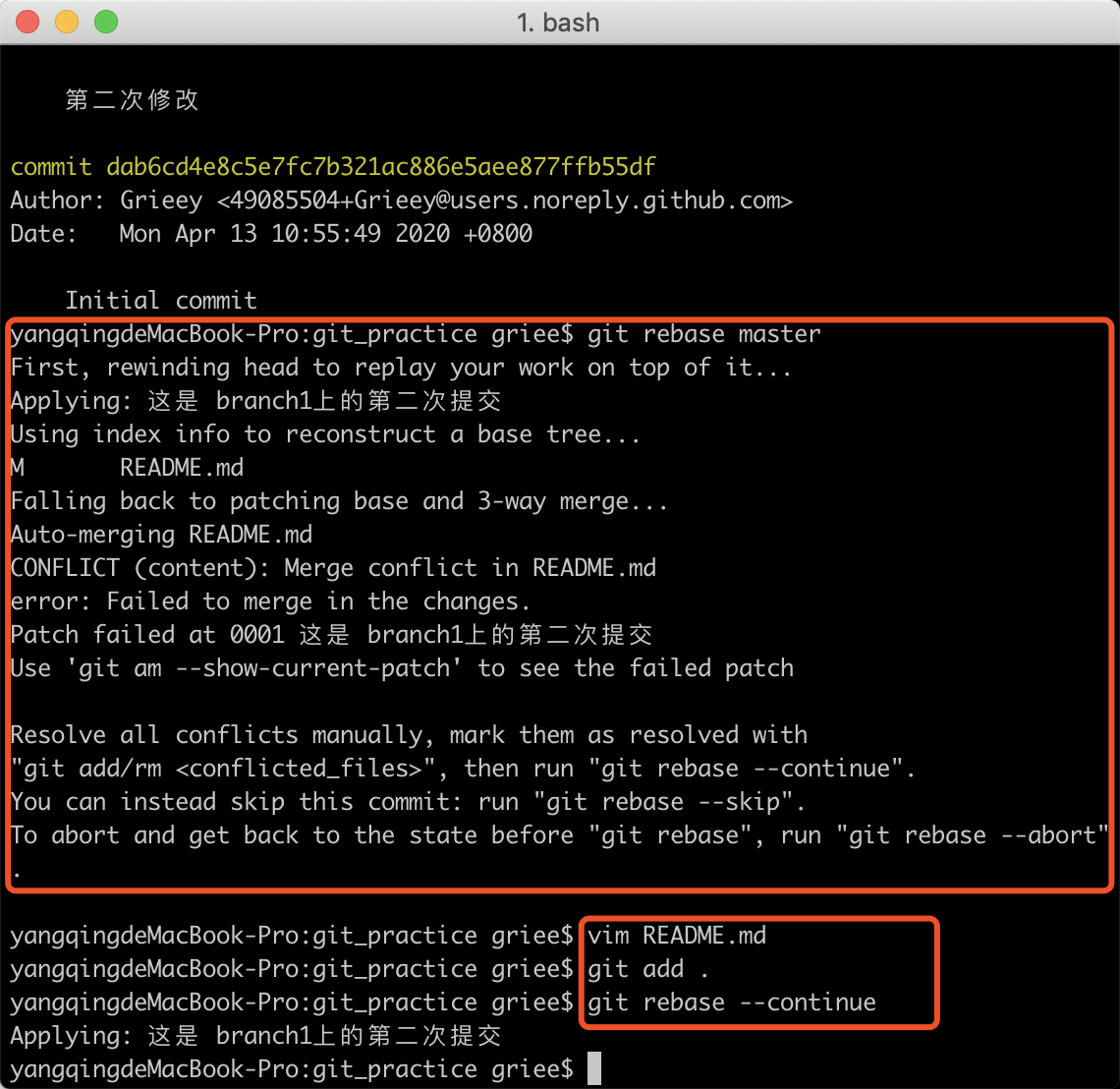
在branch1中的最新commit是这是 branch1上的第二次提交,在rebase过程中和master最新的commit产生了冲突,这个时候手动的编辑文件,解决冲突。使用add .命令将合并后的改动添加到暂存区。然后,和merge不一样的操作就是,这里需要执行不是git commit而是git rebase --continue,同理,如果需要放弃,也可以使用git rebase --abort,这里细看其实上面的命令描述中都有提示。我们解决了冲突,那就执行继续的命令。
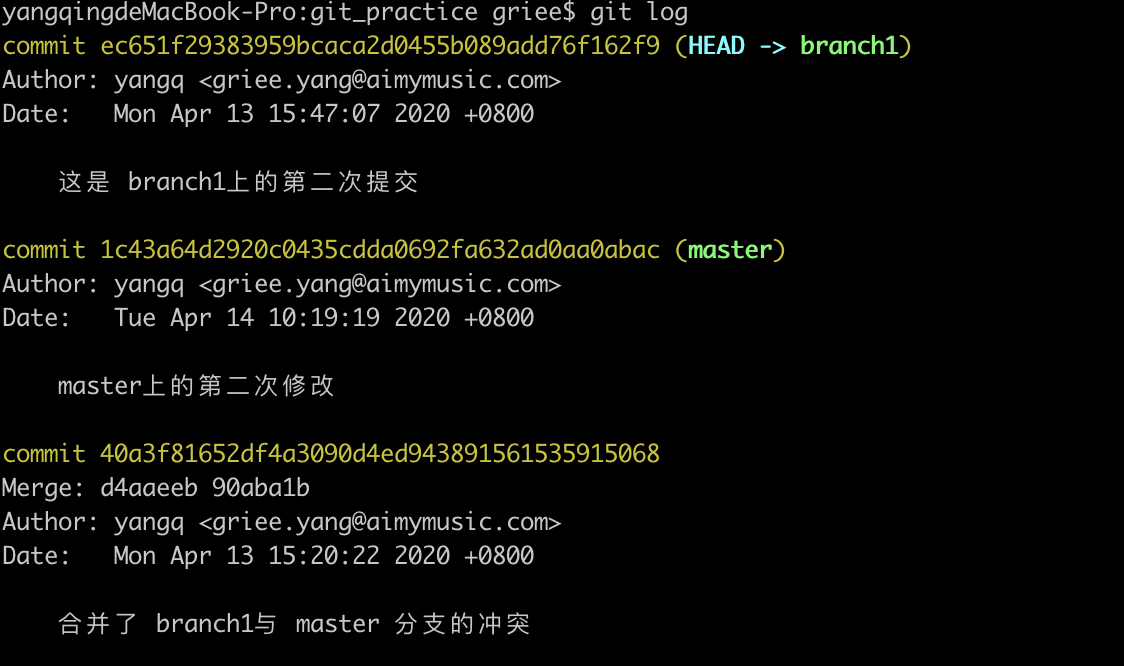
第一步完成后,查看branch1上的提交,可以看到,最新的commit后面是master的commit,所以这里的实际情况和上面的动图有一些不一样在于,这一步之后,branch1上的commits就已经变成了整合了 master上的commit的一个分支,现在的branch1已经是拥有了两个分支完整的commit了。但是,我们需要的是master分支更完整。
1 | # 执行前 master 和 branch1的情况 |
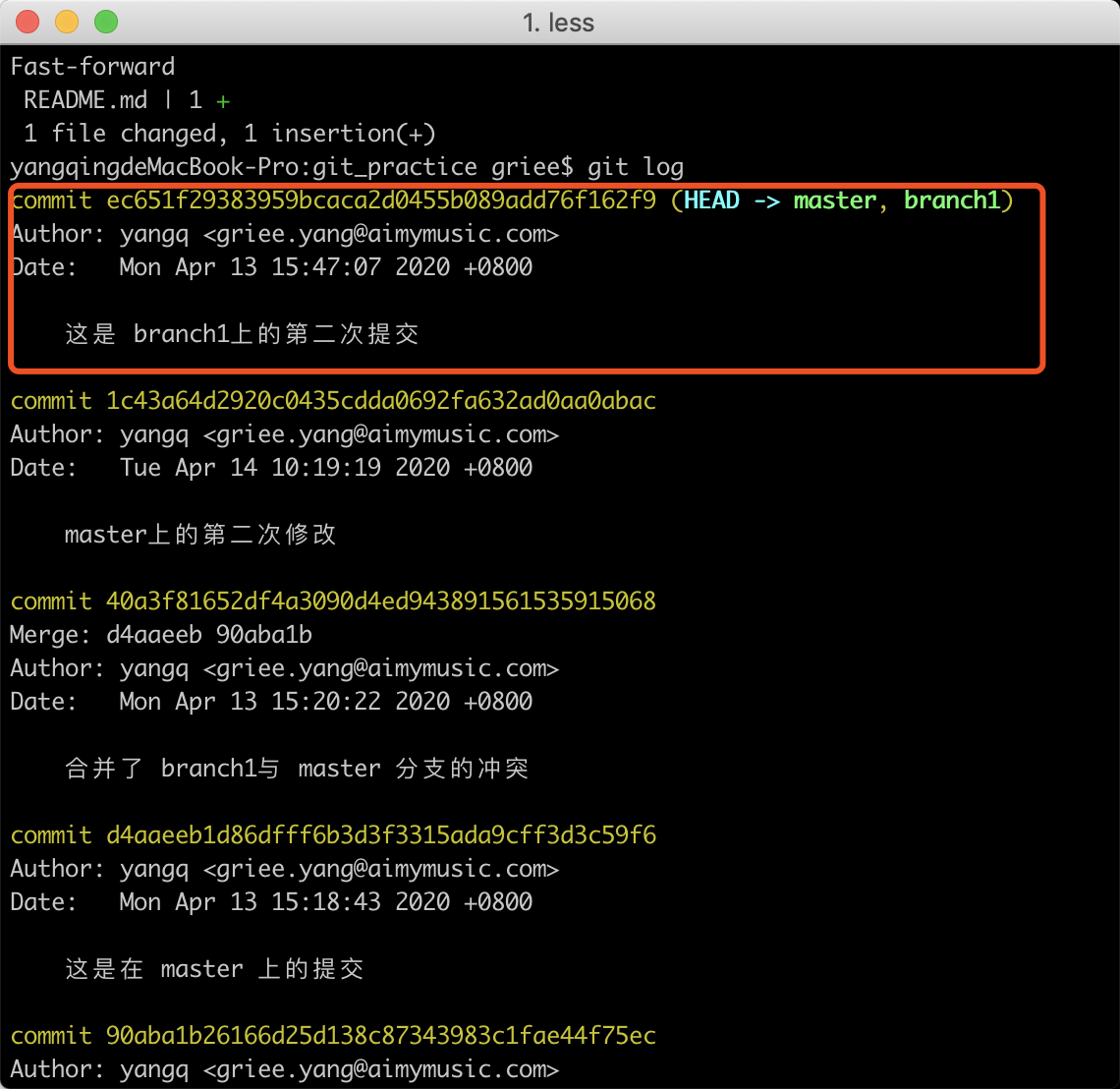
现在回到master分支,再执行merge命令就可以理解为什么是一次fast-forward了。最后的结果如下:
修正已提交的 Commit
修正最新的 commit
如果是最新提交的commit被发现有问题,git中提供了直接的命令可以修改git commit --amend。
如何使用呢,假设现在已经有一个最新的提交1,我们发现其中有几个地方写错了,那就进行修改,然后一如既往的add,现在我们需要不是把这个新提交一个commit,而是修改,所以现在就不是使用git commit -m "xxx"而是git commit --amend,
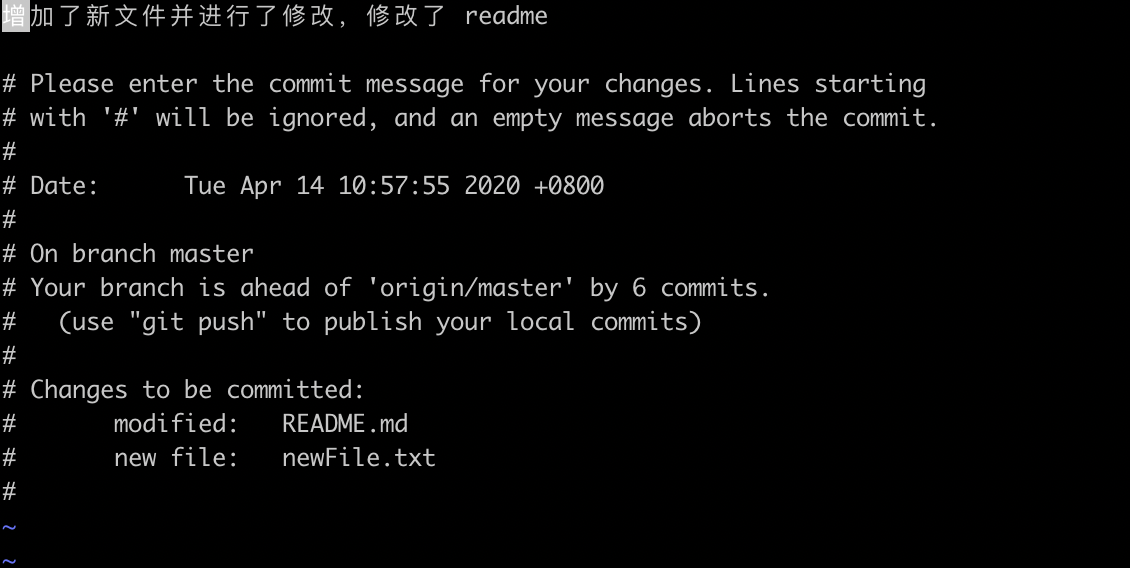
这个时候会出现一个信息编辑界面,显示着最新的commit的信息,点击i进入编辑模式,修改提交的message,然后退出保存即可,再调用git log可以看到最新的commit已经被改了。
这里有一点需要注意的是,最新的commit并不是被直接修改,而是被替换掉了,git commit --amend会生成一个新的commit 来替换最新的那个commit,在git中,每一个已经提交的commit都是无法被修改的,我们的操作只是基于一条commit链进行替换、复制和删除等等,仅仅是取消了对commit的引用和链接。
修改不是最新的 commit
当需要改正的commit不是最新的那个,上面的方法就不太适用了。这个时候需要用的是rebase -i 命令(rebase --interactive交互式rebase的缩写),这也是rebase命令的另一个比较常见的适用场景。
现在,我们假设如图的commit有了错误的提交。首先使用以下命令,将HEAD指向移动到当前commit的后面3个commit。
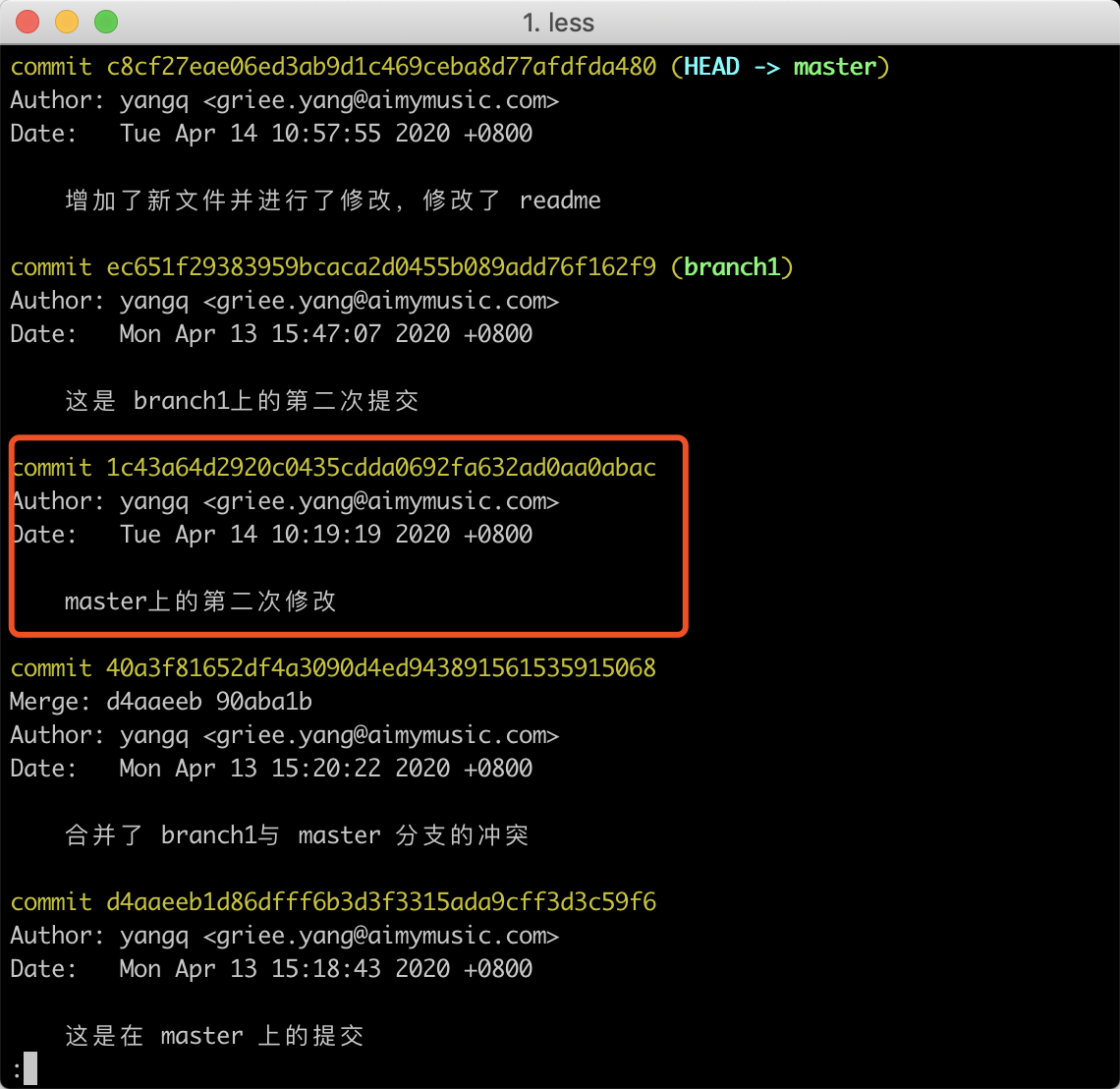
1 | git rebase -i HEAD~3 |
说明:在 Git 中,有两个「偏移符号」:
^和~。
^的用法:在commit的后面加一个或多个^号,可以把commit往回偏移,偏移的数量是^的数量。例如:master^表示master指向的commit之前的那个commit;HEAD^^表示HEAD所指向的commit往前数两个commit。
~的用法:在commit的后面加上~号和一个数,可以把commit往回偏移,偏移的数量是~号后面的数。例如:HEAD~5表示HEAD指向的commit往前数 5 个commit。
会出现下图界面
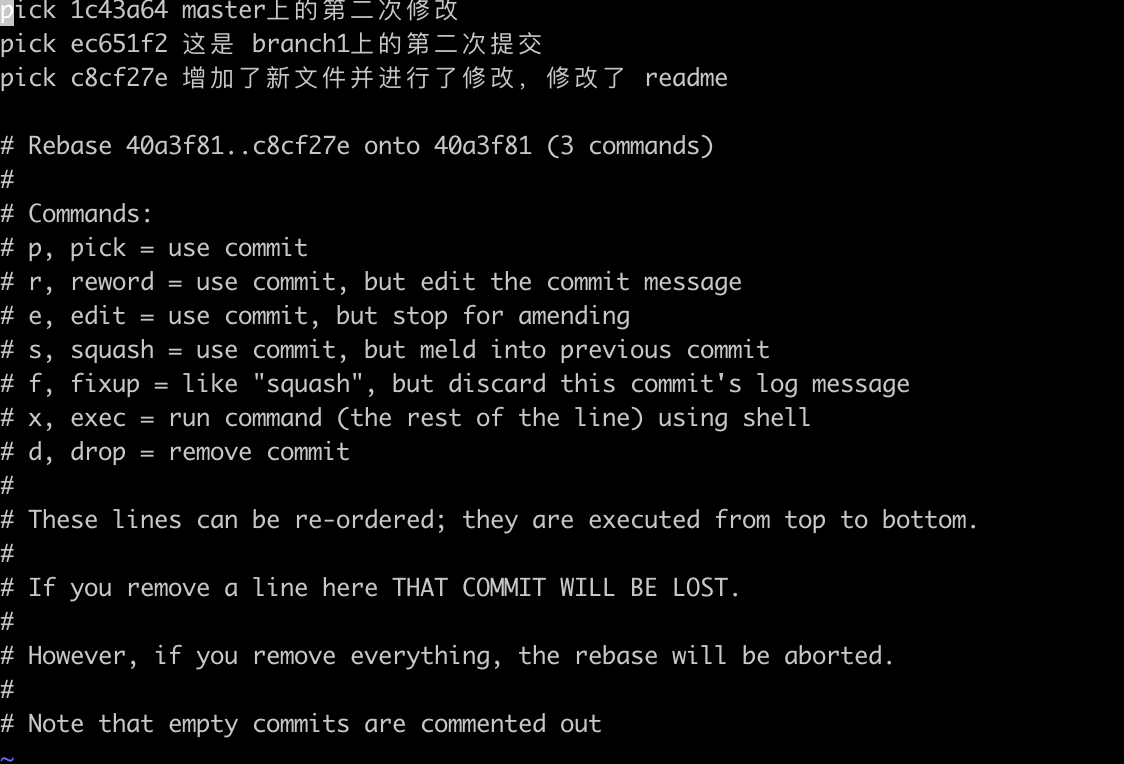
根据提示,进入编辑模式,在我们需要修改的commit前,将pick修改为edit模式。edit模式的意思就是应用当前的commit并修正。
之后退出保存,这个时候,当前的工作区中就是我们需要修改的这个commit了,和上面修改最新的commit一样,改动当前commit的内容并使用git commit --amend进行修正。完成后,git rebase --continue。
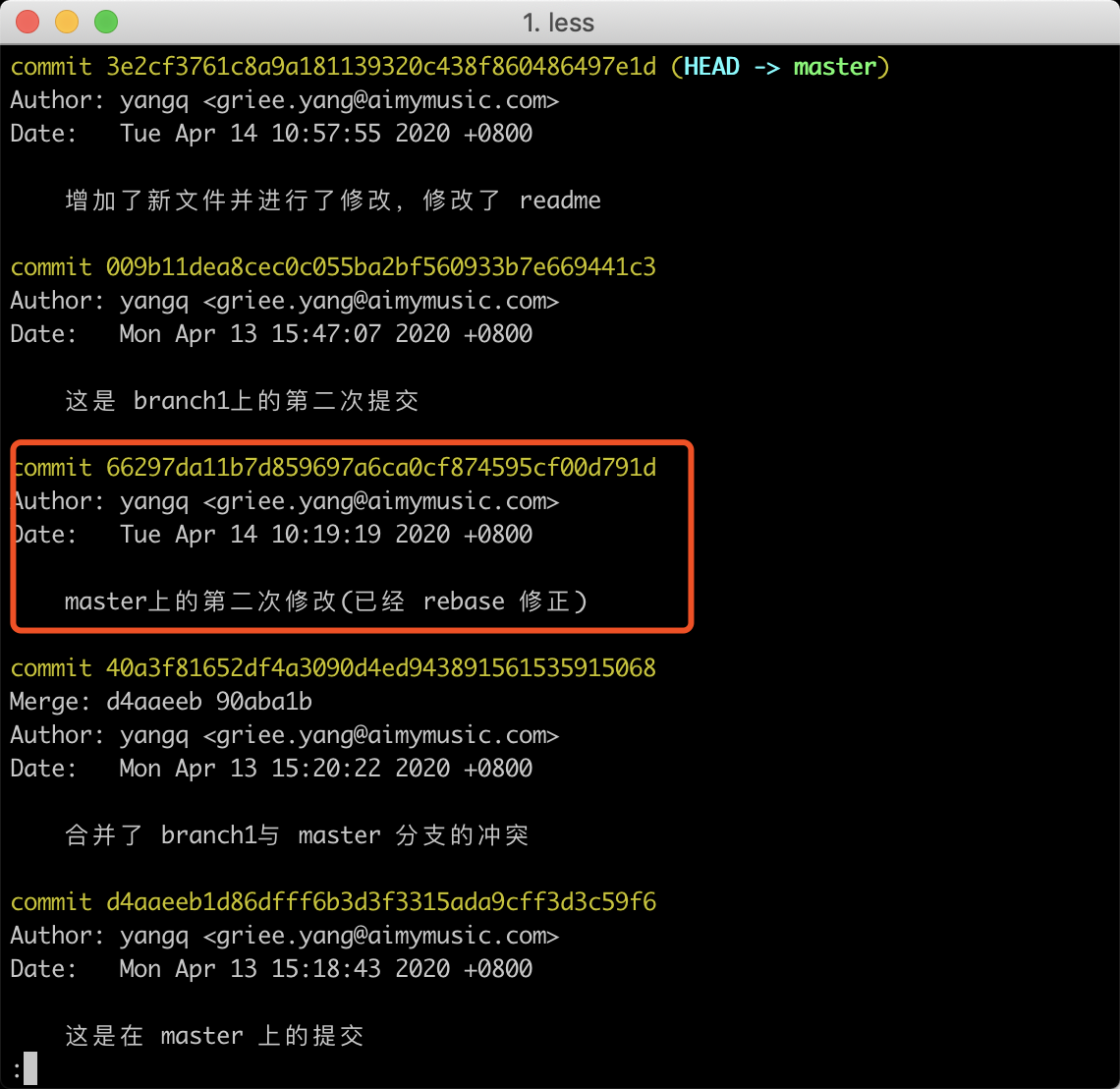
从结果上看,我们需要修正的那个commit已经被替换修改了。
丢弃 commit
1.丢弃最新的 commit
当我们因为各种原因,导致最新的commit不再是我们想要的那个commit的时候,怎么去撤销它呢
1 | git reset --hard HEAD^ |
这个命令可以将最新的commit从分支中移除掉,这样最新的commit就是之前的commit的前一条,其中几个参数说明下:
--hard这个参数主要使用的有三个值分别是hard、soft和 mixed,区别在于。使用--soft模式,会修改版本库中的记录(从branch中移除该commit),但是会保留暂存区和工作区,也就是将本地版本库的头指针全部重置到指定版本,且将这次提交之后的所有变更都移动到暂存区。使用--hard模式,三者都会被重置,一定需要注意。 而不加参数时,默认使用的是--mixed,这种模式下是,保留工作区,清除暂存区。
这里再讨论下更复杂的一种情况,那就是如果我丢弃的内容中,有一部分是想要的或者我还需要对照着查看。可以分为三种情况:
- 已经
commit了,这种其实是最常见的一种情况,因为有SHA-1值,可以使用git reflog来查看我们操作的历史,找到刚刚commit的SHA-1值就可以找到被丢弃的那个commit。(需要注意的一点是,对于没有引用的commit,git会在一定时间内进行自动清理) - 还没有
commit,但是 添加到了暂存区中。这个就麻烦一些了,因为没有生成对应的SHA-1值,无法通过第一种情况的方法找到,就需要使用另一个的命令git fsck --lost-found操作,如果返回成功的结果,我们就可以在.git/lost-found/目录中找到刚刚丢弃的文件。 - 连暂存区都没有添加到,这种情况下,只能靠IDE的本地历史记录来寻找了。
参考文章:Git reset 后的数据恢复操作
其实,对于reset命令来说,它的本质是移动 HEAD 以及它所指向的 branch,撤销对其只是在本质上附带开发的一种功能而已。但是这一点上好像和checkout命令有点相似,区别是checkout没有改变所指向的branch,是的,这确实是他们最大的区别,使用checkout命令签出某个branch(前面也说过,对于工作区来说这其实也是签出某个commit,但是在指向中,是有区别的,一个是指向了branch,一个是指向了commit)或者commit时,它所改变的仅仅是HEAD的指向。所以这里,还有一种命令
1 | git checkout --detach |
这行命令的效果就是,仅仅让HEAD脱离了指向branch,而直接指向了commit。
丢弃不是最新的 commit
这个需求有两种命令可以实现:
这个从理论上来说,本质上和修改不是最新的
commit是一样的。使用git rebase -i的命令,查看需要修改的几个commit,和修改不一样的在于,修改时我们是修改pick为edit。这里现在有两种做法,一个是将需要丢弃的commit那行直接删除,这样在rebase命令执行过程中就会过滤掉被删除那行的commit,还有一种更标准的做法就是将pick修改为drop。最后再执行git rebase --continue即可。关于drop和删除一行的讨论,在科学传送门这里有一些讨论可以参考。使用
git rebase --onto命令在使用
git rebase命令时,git会自动的选取起点,这个起点选取的方法就是当前的commit和目标的commit在历史记录上的交叉点作为起点(上面使用rebase命令的时候,都是如此)。而给rebase命令添加了--onto参数后,就可以指定起点。假如现在有如下的提交记录。1
2
3a-->b-->c-->d master
\
e-->f-->g branch1需求上,在合并
branch1时,只需要合并f, g两个commit,就可以这样使用1
git rebase --onto d e branch1
注意,
rebase命令在执行时,会排除起点的commit,也就是e这个commit。最后的结果就想下面这样,f1,g1是内容和f,g相同的commit1
2
3a-->b-->c-->d-->f1-->g1 master
\
e-->f-->g branch1那么,同理,也可以使用
--onto来执行撤销的操作。同样是这样的提交记录1
2
3a-->b-->c-->d master
\
e-->f-->g branch1现在需要撤
f所对应的commit就可以这样写1
git rebase --onto e f branch1
这个翻译下就是,将起点设置为
f,然后branch1作为终点,这一条路径上的commit节点都应用到e之后,这样出来的结果就会没有f。
修改已经 Push 的 commit
如果
push的分支是自己的分支,那么可以暴力一些,先使用上面的方法修改掉本地的commits,然后再push,需要注意的是,这个时候直接push是会出错的,需要使用强制的参数1
git push origin branch1 -f
-f这个代表force执行的操作(强制性),这种操作尽量少用,如果没有搞清楚就强制去覆盖远端的commit在多人协同的时候,很容易对同事的commit造成混乱。如果
push的内容已经合并到了其他的分支,git revert HEAD^这个命令可以创建一个新的commit,它的内容和倒数第二个commit是相反的,从而和倒数第二个commit相互抵消,达到撤销的效果。在revert完成之后,把新的commit再push上去,这个commit的内容就被撤销了。它和前面所介绍的撤销方式相比,最主要的区别是,这次改动只是被「反转」了,并没有在历史中消失掉,你的历史中会存在两条commit:一个原始commit,一个对它的反转commit。
恢复已删除的分支
有时候,不管有意无意,都可能误删了分支,一定要及时找回。操作步骤如下:
1.使用git reflog命令查看HEAD移动的相关记录,这个记录最新的在最上面,找到与branch1相关的记录,如图,可以看到最后一次从branch1移动到master的记录,那么这条记录之前的commit肯定是branch1上的一条commit。
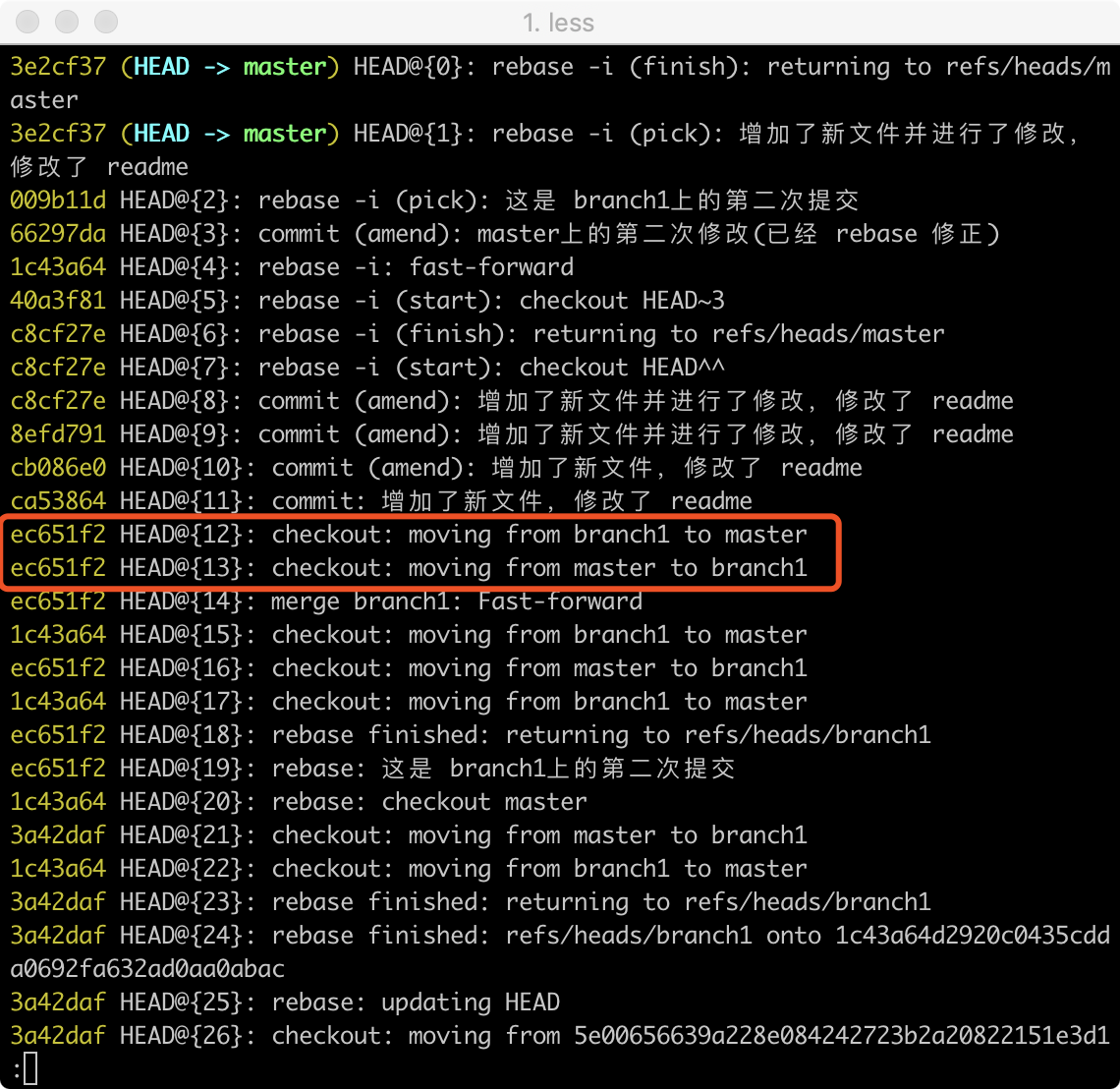
2.签出这个commit,并在该commit上建立之前误删的分支即可。
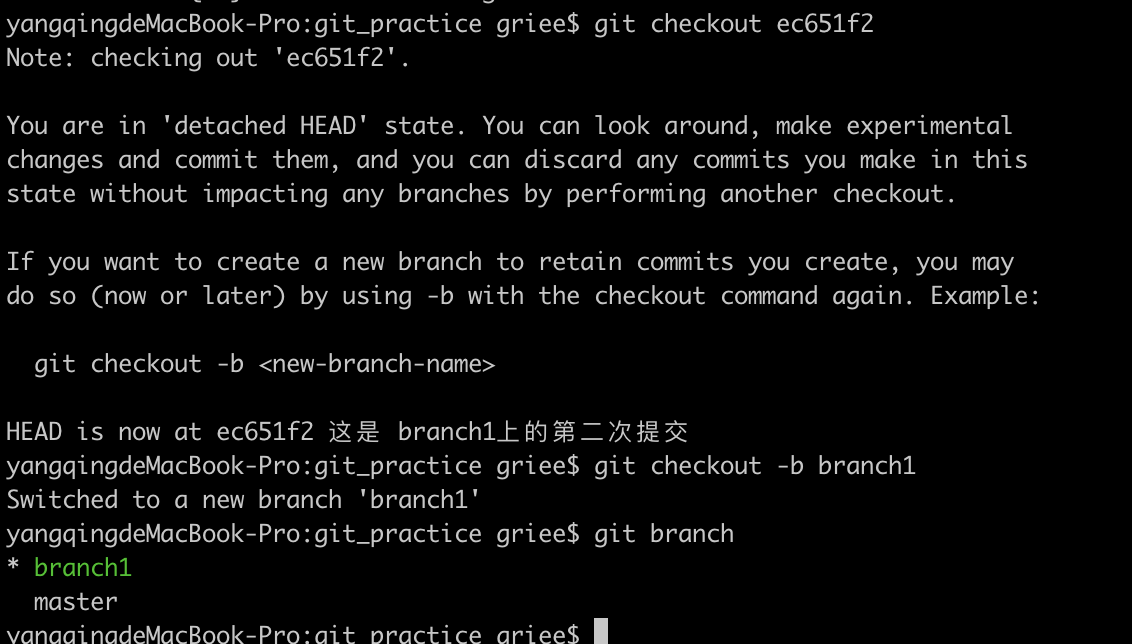
依然需要注意的一点:git 会定期回收无引用的commit,所以这个操作需要及时。
临时暂存
有时候,在不同分支工作时,需要偶尔切到其他分支看一行代码,或者调试个 bug 啥的,我们都是提交一个临时的commit再去切,这样算是一个保险的做法。还有更优雅一点的做法就是git stash命令,这个命令可以将目前工作区的改动都临时保存在一个独立的地方,等你搞好了其他的工作,再回来时,使用git stash pop就可以恢复了。
如果临时暂存时,存在未被追踪的文件,需要加上-u 的参数,如下
1 | git stash -u |
注意:没有被 track 的文件(即从来没有被 add 过的文件不会被 stash 起来,因为 Git 会忽略它们。如果想把这些文件也一起 stash,可以加上
-u参数,它是--include-untracked的简写。
Tag的使用
tag就是标签,当我们在一个分支上构建了不同版本的应用时,可以通过tag来进行标记。这是一种基础的用法,
1 | git tag -a v1.0.0 -m 'xxx build version' |
其实,git 的tag还可以用于自动化的构建和测试当中,本地打好了tag后,推送到远端仓库,在远端仓库中部署CI等自动化的脚本,可以检测到相应的tag来进行一系列的自动化操作。但是这个更多的是自动化构建方面的知识,有兴趣可以了解了解。
相关文章: