Jan 26, 2021
Handler学习总结
那么回想一下我们最开始学习Java时,就是编写一段有输入输出的GUI程序:写完后运行起来->我们输入数据->程序处理输入数据->输出结果->程序结束。这是最简单的一个程序,他在处理完成我们的任务后,是会结束的!而且刚开始学习的时候,老师也会告诉我们,写循环的时候需要注意循环的条件,不要写死循环,这样程序就会卡死在那儿。那个时候其实不太理解这种卡死真正是什么,感觉像刚接触电脑时那种点哪儿都没有反应,现在回想起来,那种卡死是假象,并不是生活中的某个东西卡住了不动了。而且程序一直在运行,运行着你的循环中的代码。所以,当你的循环的代码能够不停的处理不一样的事件,那样不就能一直处理新的需求了。如果没有循环,单线程上的代码执行完,程序就结束了。
所以说循环是让程序能一直运行的一个基础,但是对于单线程来说,循环里的东西是固定的,那这样只是在不断的处理同一个东西而已,并没有什么意义。所以肯定需要多个线程来产生不同的东西,然后交互信息,这样才能源源不断的处理新的东西,我们把这个信息封装一下就可以称为消息了,而多个线程交互这个信息其实就是线程间通信了,这个通信的基础就是多个线程都能访问到同一资源(这个资源就是通信的媒介)。
这样一想,这个工作模型就是生成者-消费者模型呀。以工厂为例子,生产者就是生产零件的,消费者就是组装零件的。我们可以把应用看着一个消费者,Looper的死循环就是传送带。这样,生产者可以是系统,产生新的刷新信号,也可以是用户,触摸屏幕产生新的事件,他们在不同的传输带工作(线程),当他们完成他们的零件生产后,就将零件(事件)包起来(封装到消息)中,通过工人(Handler)将消息放到传送带上。这样就完成了两个传送带的通信了对不对,生产的传送带将某一批号的零件生产成功的信息通过包装放到另一个传送带上,那么另一个传送带处理该包装时,就知道了该批号零件生产成功的信息,接着按照包装上的说明书去组装他们(处理消息)。
接着我们就从源码的角度来看看Android中整个机制是如何具体运行的。
整体流程
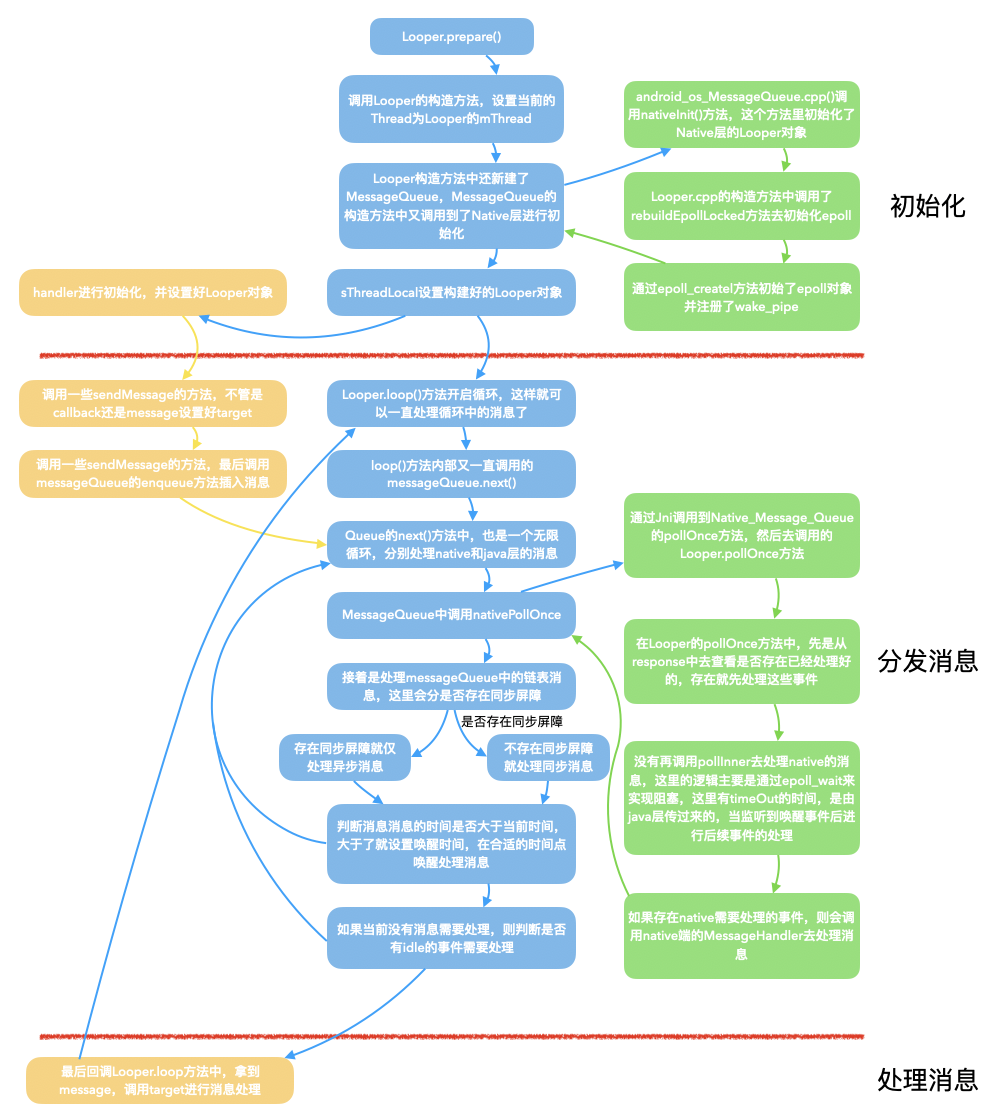
图中涉及到的一些对象:
- Handler:本质上是作为一个工具类,暴露API给外部调用,其内部的消息管理都是交给了Looper去具体执行。作为开发者只需要关注使用
handler对象去发送消息和处理消息。 - Looper(蓝色框中的):具体做消息的分发处理的
工具人,作为Java层中的话事人去,连接着消息的发送者和处理者Handler、消息队列的维护者MessageQueue及线程的信息。一个线程中只有一个Looper对象存在。 - MessageQueue:维护消息的队列,同时还负责与Native层进行通信。
- Message:消息的抽象类,内部存储着具体的消息内容,消息的类型(同步或者异步),消息的时间和Callback、handler对象等等。
- NativeMessageQueue:Native层中的消息管理者的角色,承担了类似Java层中的handler部分职责,Java层可以通过Jni调用到该对象中的方法。在Native层中也存在Looper(绿色框中的)和handler对象,用于处理Native层的消息。
- MessageHandler:Native层中的消息处理者。
- epoll:linux中的IO多路复用机制,性能优于select机制和poll机制。
源码分析
初始化
这里我先不按照流程来看代码,从开发者使用的角度来分析源码,首先接触的是handler的初始化:
[frameworks/base/core/java/android/os/Handler.java]

在Handler的构造方法中,调用了Looper.myLooper()方法获取Looper对象赋值给Handler,从这里可以看出,在线程中使用Handler需要先初始化好Looper对象,因为Handler本身就是为了线程通信而服务的,如果线程相关的信息都没有准备好,这服务也就没有意义了。
[frameworks/base/core/java/android/os/Looper.java]

继续跟代码来看看这个Looper.myLooper()干了啥,从上面代码看,就是从sThreadLocal中获取Looper对象实例。这个sThreadLocal的类型为ThreadLocal<Looper>对象,他是JMM中每个线程的私有内存所存储的东西的具体实现(ThreadLocalMap,一种类似Map的结构,以Thread为Key,存储对应的Value),关于ThreadLocal的传送门有更多了解可以去这里看看。因此每个Handler内的消息队列所维护的都是本线程中的所有消息。
这个sThreadLocal的上面还有一句注释,就是说在调用get()去获取Looper对象时,应该先调用过prepare()这个方法,去具体看看:
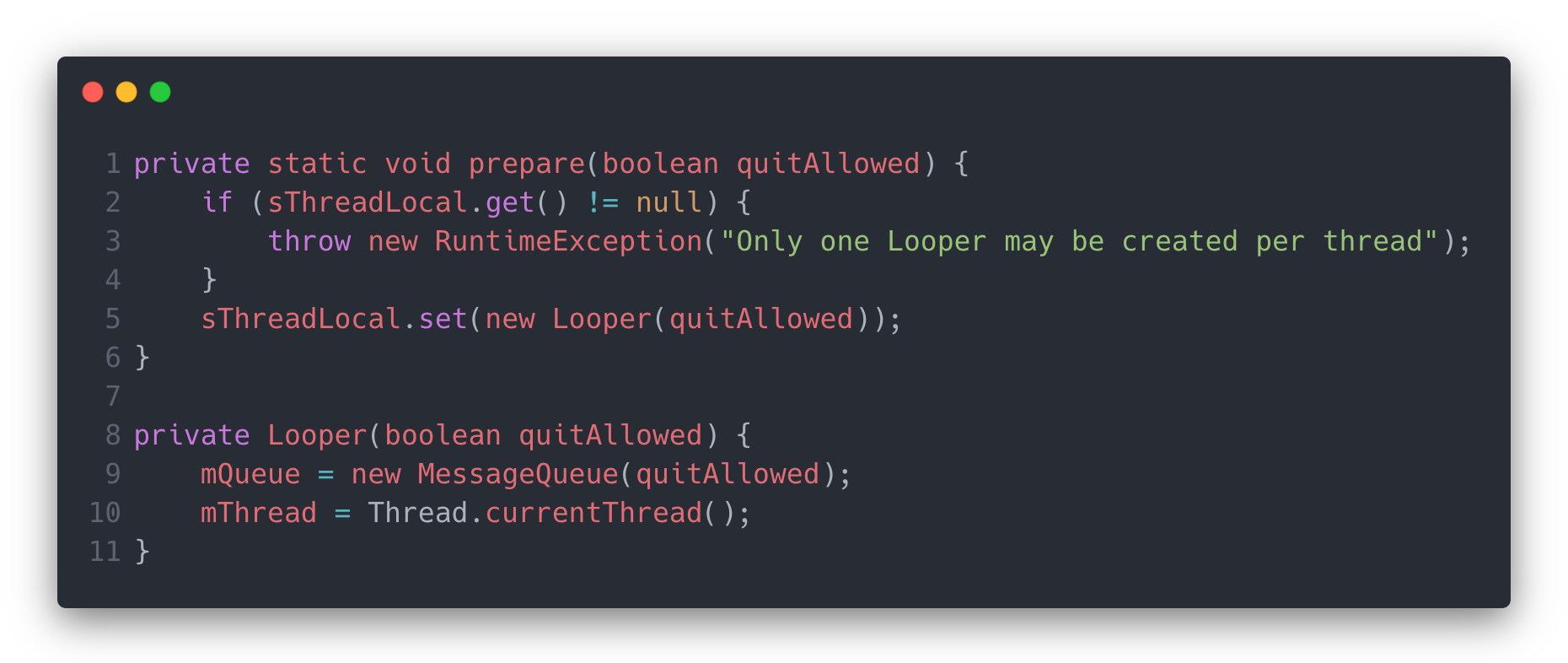
在这个方法里,主要做了三件事:
- 调用
Looper的构造方法生成一个实例。 - 在
Looper的构造方法中,新建了messageQueue对象,并绑定了线程。 - 将实例设置到
threadLocal中。
这样,对Looper来说它的初始化工作算完成了。上面的代码还有一个细节就是sThreadLocal.get() != null的判断,也说明了对于一个Looper来说,只能调用一次prepare()方法。
接着是MessageQueue的初始化,主要是通过Jni调用了一个Native方法。
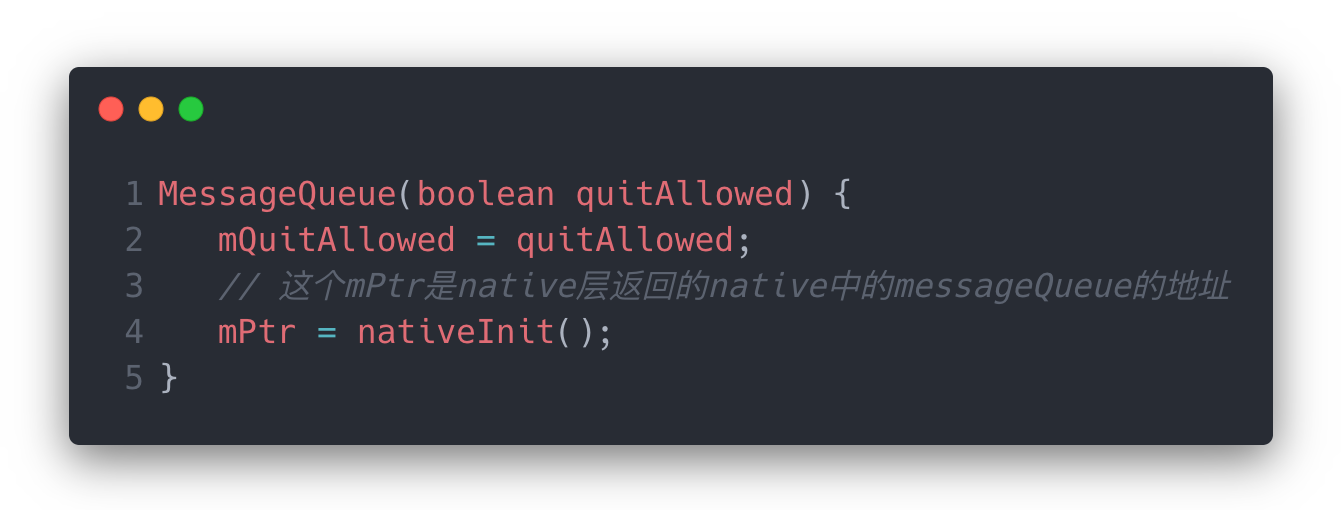
在Native中调用到的是android_os_MessageQueue.cpp中的方法
[frameworks/base/core/jni/android_os_MessageQueue.cpp]
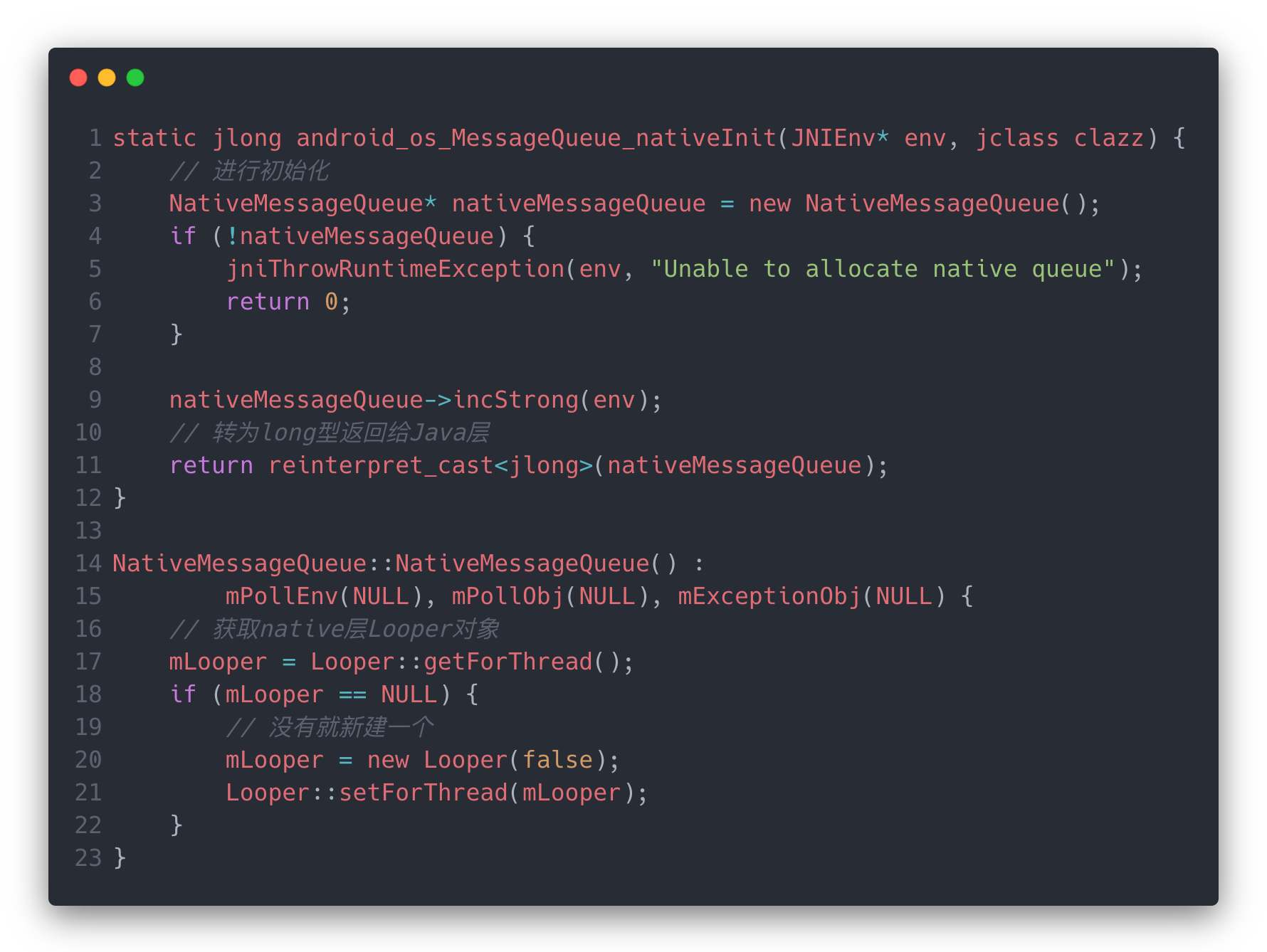
NativeMessageQueue的构造方法主要是设置NativeLooper对象(为了和Java层的Looper做一下区分,这里加一个Native的前缀)。感觉这里的NativeMessageQueue有点像Handler的意思。
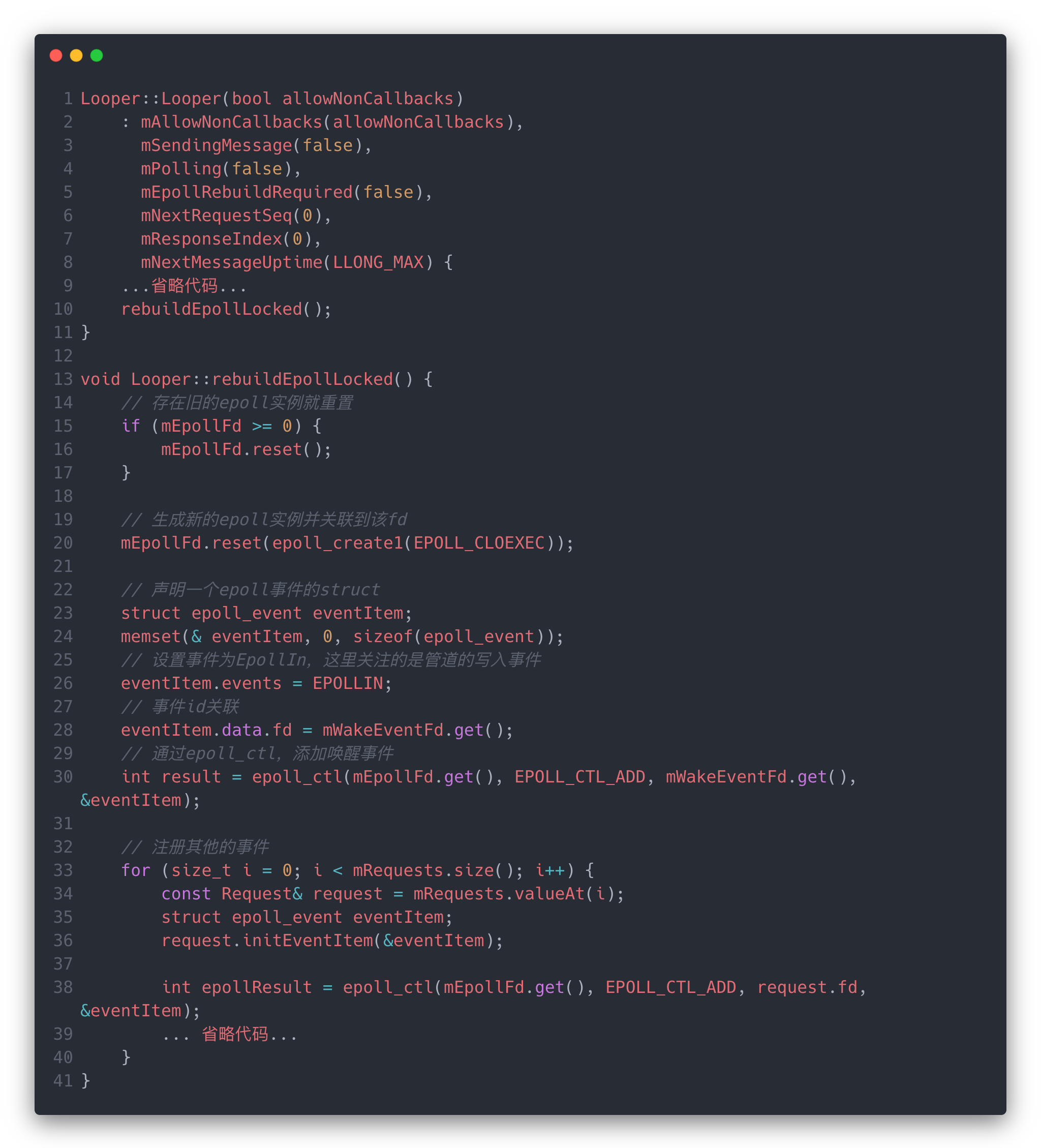
在NativeLooper的初始化中主要是做了Epoll初始化相关的操作。创建了Epoll的实例,并注册了唤醒事件和其他事件到Epoll中。这里涉及到的是epoll_create和epoll_ctl两个函数,前者会创建一个空闲的fd并将他们关联在一起;后者可以注册一些事件进行监听。
这里简单说一下,对于epoll的使用基本上分为三步:
- 通过
epoll_create创建并关联空闲fd; - 通过
epoll_ctl添加我们想要监听的事件到epoll中; - 通过
epoll_wait去等待我们监听的事件发生。
在整个初始化过程中,前面两步已经准备好了,在下面的流程中就会用到第三步。Epoll机制涉及到就是Linux内核相关的一些知识了,可以看看袁辉辉大佬写的源码解读epoll内核机制。有能力的小伙伴也可以直接阅读源码去分析它的工作机制epoll源码
Epoll在这里的作用就是生产者-消费者模型中的阻塞机制,当生产者没有生产出消息时,消费者(线程)就需要调用epoll_wait等待;消费者发出消息后,可以通过写入唤醒事件,在Epoll中监听到写入事件后,epoll_wait方法就会返回事件给消费者-线程,也就可以继续执行消息的处理逻辑,然后再循环到epoll_wait等待下一条消息。
至此,整个准备工作就完成了,接着就是运行起来整个机制。调用Looper.loop()方法,该方法就是前面介绍的死循环,所以我们的所有事件和消息处理都在这个循环中。
发送消息
当我们在线程中拿到Handler的实例时,可以调用一系列方法去发送消息,不管是发送我们自己obtain()的消息还是runnable,到Handler内部都会封装为一个Message进行传递,runnable会设置到message的callback中。
而在Handler内部,一系列方法,最后都是调用的sendMessageAtTime,而sendMessageAtTime方法调用了enqueueMessage。
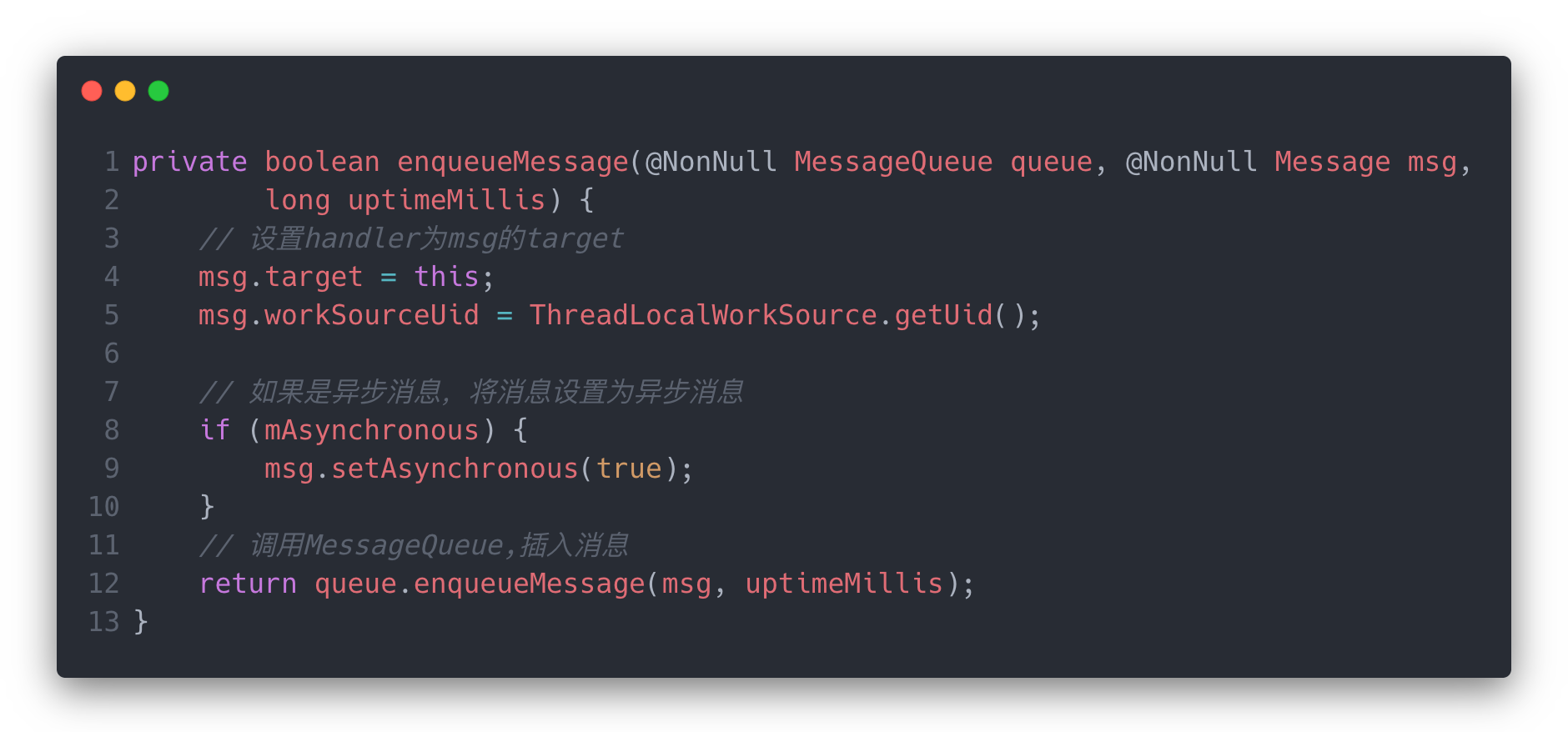
这一步中,将message的几个关键信息进行了设置,最重要的就是target = this,将当前的handler对象设置为了消息的target,这个作用是以便后面取出消息的时候,知道找谁去处理他。虽然一个线程中Looper只有一个实例,但是我们可以创建多个Hanlder的实例来进行消息的发送和处理,所以这个的目的是将发送方和处理方通过消息关联。
继续跟代码到MessageQueue。enqueueMessage()
[frameworks/base/core/java/android/os/MessageQueue.java]
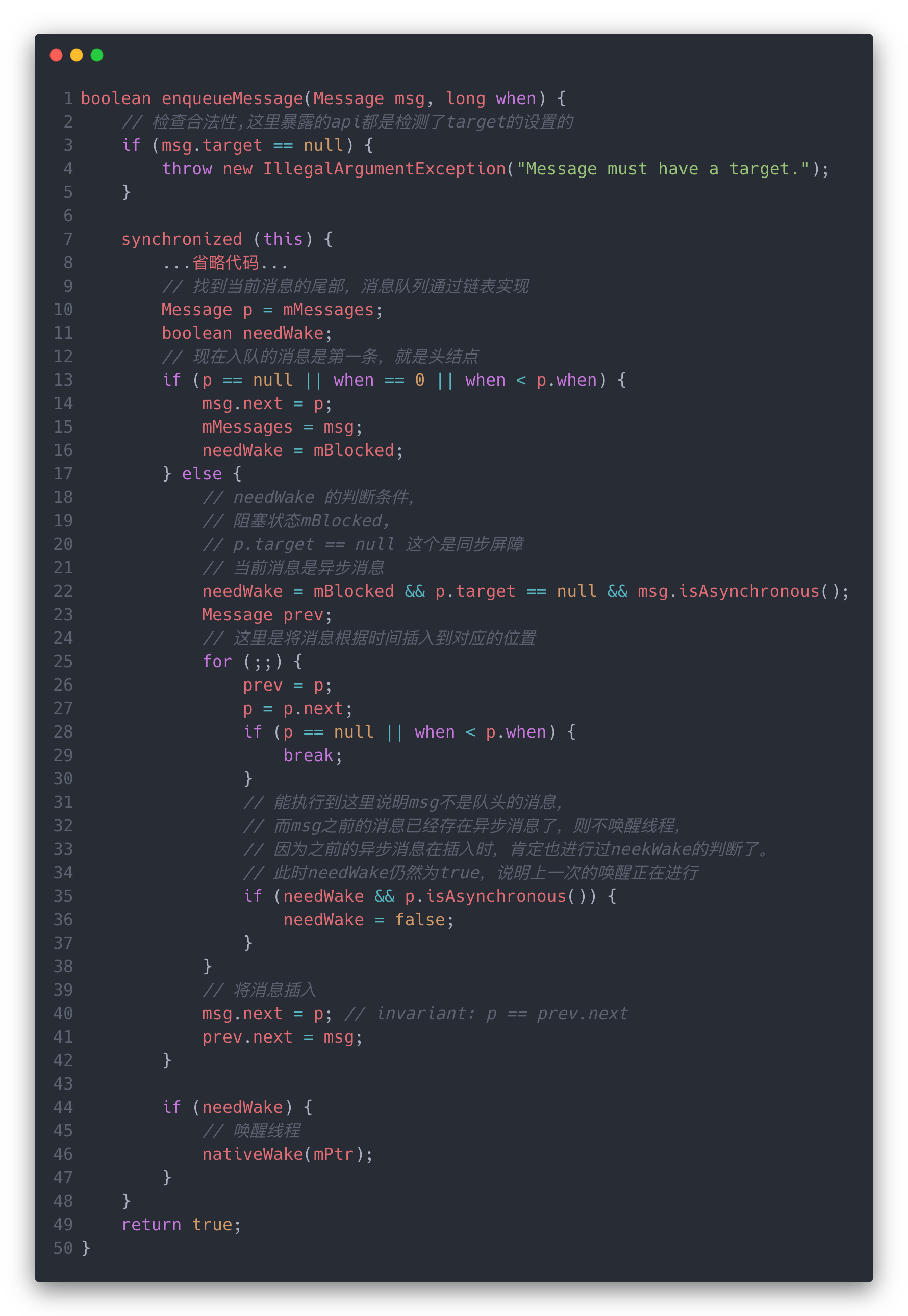
这一个方法中的逻辑主要是根据消息时间将消息插入到合适的位置,同时根据消息队列的情况看是否需要唤醒线程。
对于唤醒的逻辑,我是这样理解的:
- 第一种情况是如果当前队列没有消息,那么新消息就是队头,这个时候是否需要唤醒当前线程需要根据
mBlocked的状态(这个状态的设置可能是之前的消息队列为空了,所以没有消息处理,就被Native阻塞了); - 第二种情况就是看是否满足需要处理异步消息的判断,也就是存在同步屏障并且当前消息是异步消息时,如果当前仍然是阻塞状态,那么就需要立刻唤醒线程来处理这条优先级高的异步消息了。
额外的一个逻辑:这个循环里面有个将needWake置为false的判断,这个判断中如果needWake为true了,说明前面的mBlocked && p.target == null && msg.isAsynchronous()是true,而且执行到这一步了,也说明了现在的队列不为null了,再看第二个条件是p.isSynchronous(),综合一下就是之前已经存在需要唤醒线程的异步消息了(也就是这条p.isAsynchronous()的消息也经过mBlocked && p.target == null && msg.isAsynchronous()的判断,但到当前消息判断时,线程仍然为Blocked状态,说明上一条的唤醒还没有成功,处于唤醒的过程中),所以需要重置needWake来避免重复唤醒。
[frameworks/base/core/jni/android_os_MessageQueue.cpp]

最后看看唤醒线程的代码,这里会通过mWakeEventFd写入一个8字节的数据,这个时候epoll_wait会收到写入事件,然后返回值给nativie中Looper循环,就可以继续遍历消息了,这个逻辑在接下来的分发消息中就会涉及到了。TEMP_FAILURE_RETRY是一个重复尝试,直到成功的方法。
分发消息
分发处理消息主要是Looper.loop()方法里的逻辑

Loop()方法的逻辑比较简单,调用queue.next()去获取下一条消息,然后调用msg.target.dispatchMessage(msg)去处理它。
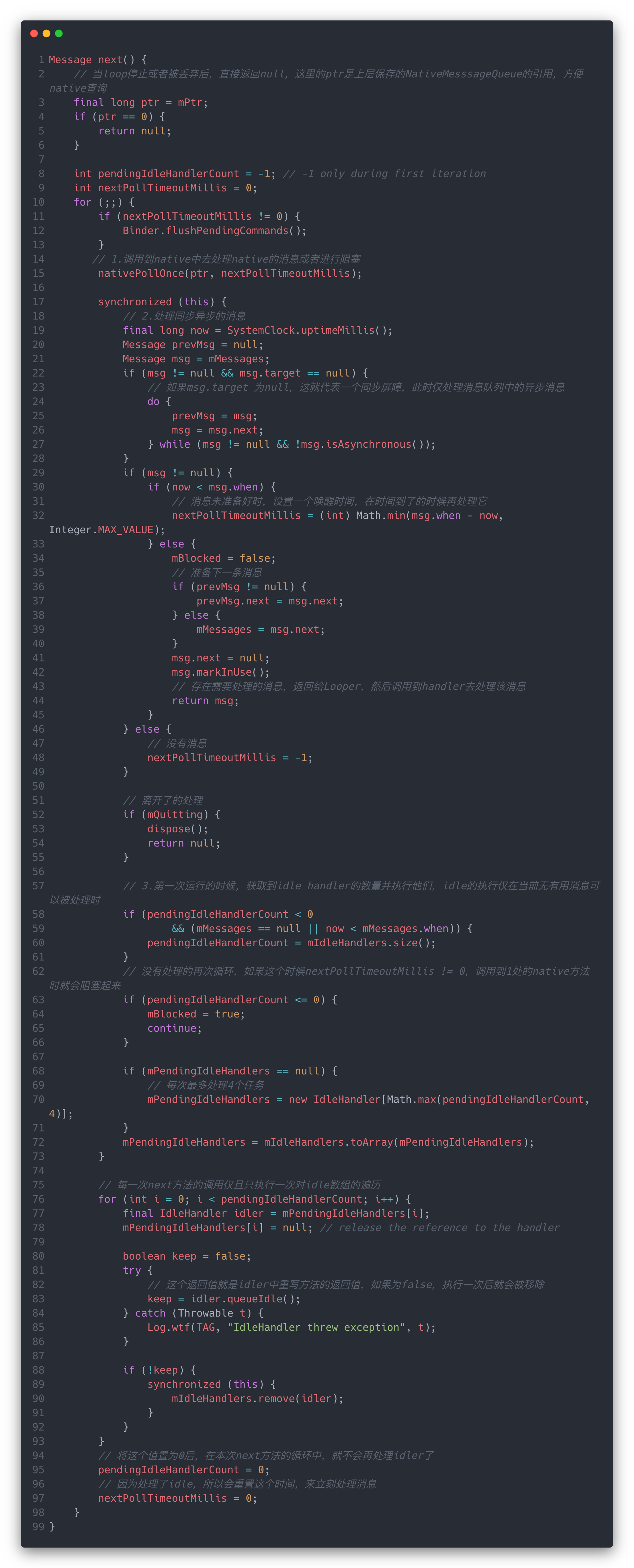
next()方法中的逻辑比较长,大致可以分为三个部分:调用到Native层、处理同步异步消息和执行idle任务。上面的代码是一个总览,可以从头到尾的看一下整个流程。下面就分别说说三个部分的具体逻辑。
首先看调用到Native的处理。nativePollOnce()方法,传入了mPtr和nextPollTimeoutMillis这两个值,前一个是nativeMessageQueue的地址,在messageQueue构造函数中从Native返回过来的,这里传回去方便操作Native对象,后面一个nextPollTimeoutMillis就是Java层需要的延时唤醒时间了,这个值有值说明Java层的消息需要延迟处理。该方法在native中直接调用到了nativeMessageQueue的pollOnce,进一步调用了mLooper的pollOnce。我们就直接来看mLooper的源码。
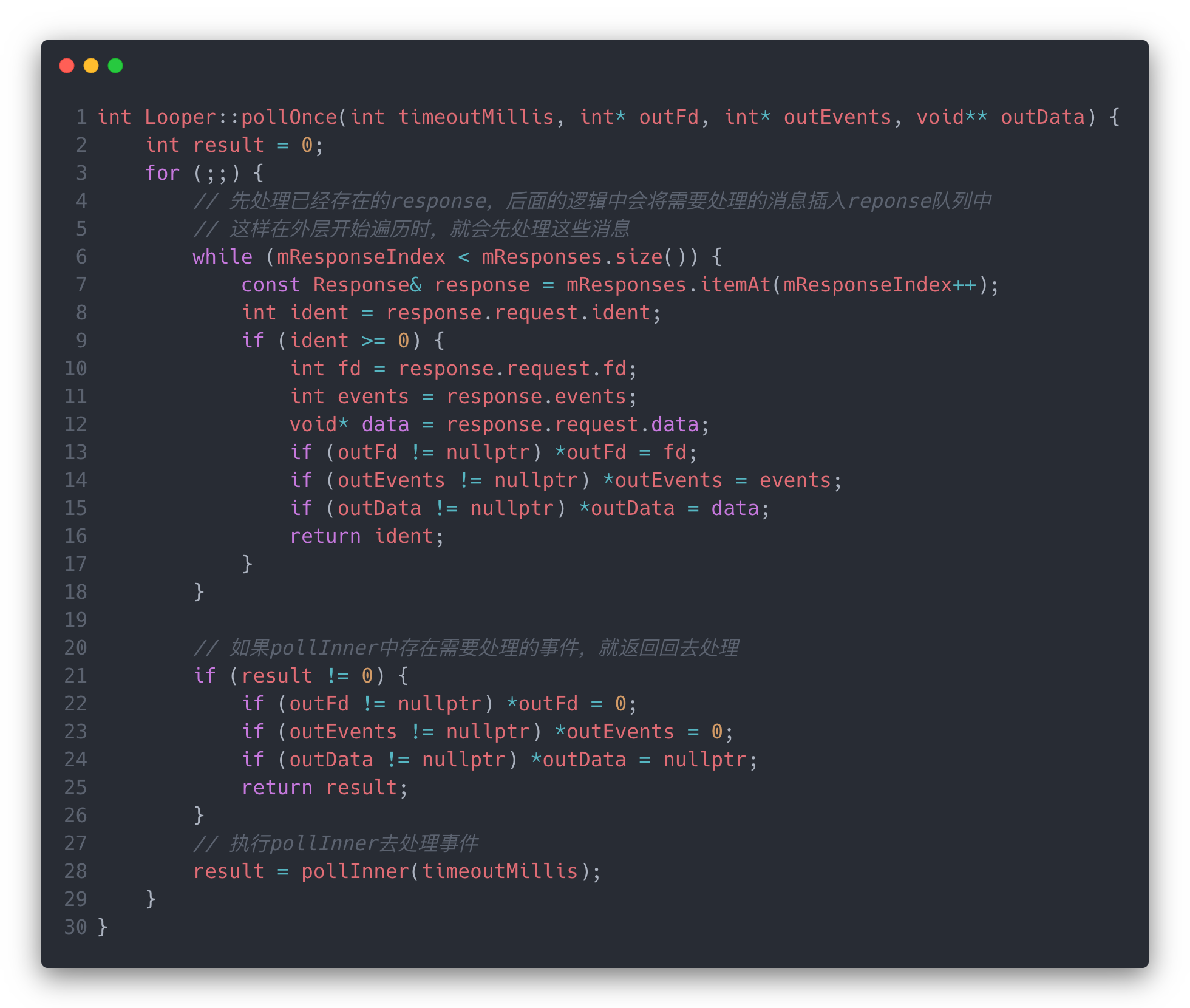
这个方法里也是一个死循环去处理消息,前面遍历response是处理当前接收到的非唤醒时间的请求,这个可以在polllInner方法的逻辑中看到,当epoll_wait接收到的不是唤醒事件,而是其他事件时,会先将事件处理并添加到mResponse数组中去,这个时候,当新的循环遍历到来就可以去处理它们了。
接着是进入到pollInner中:
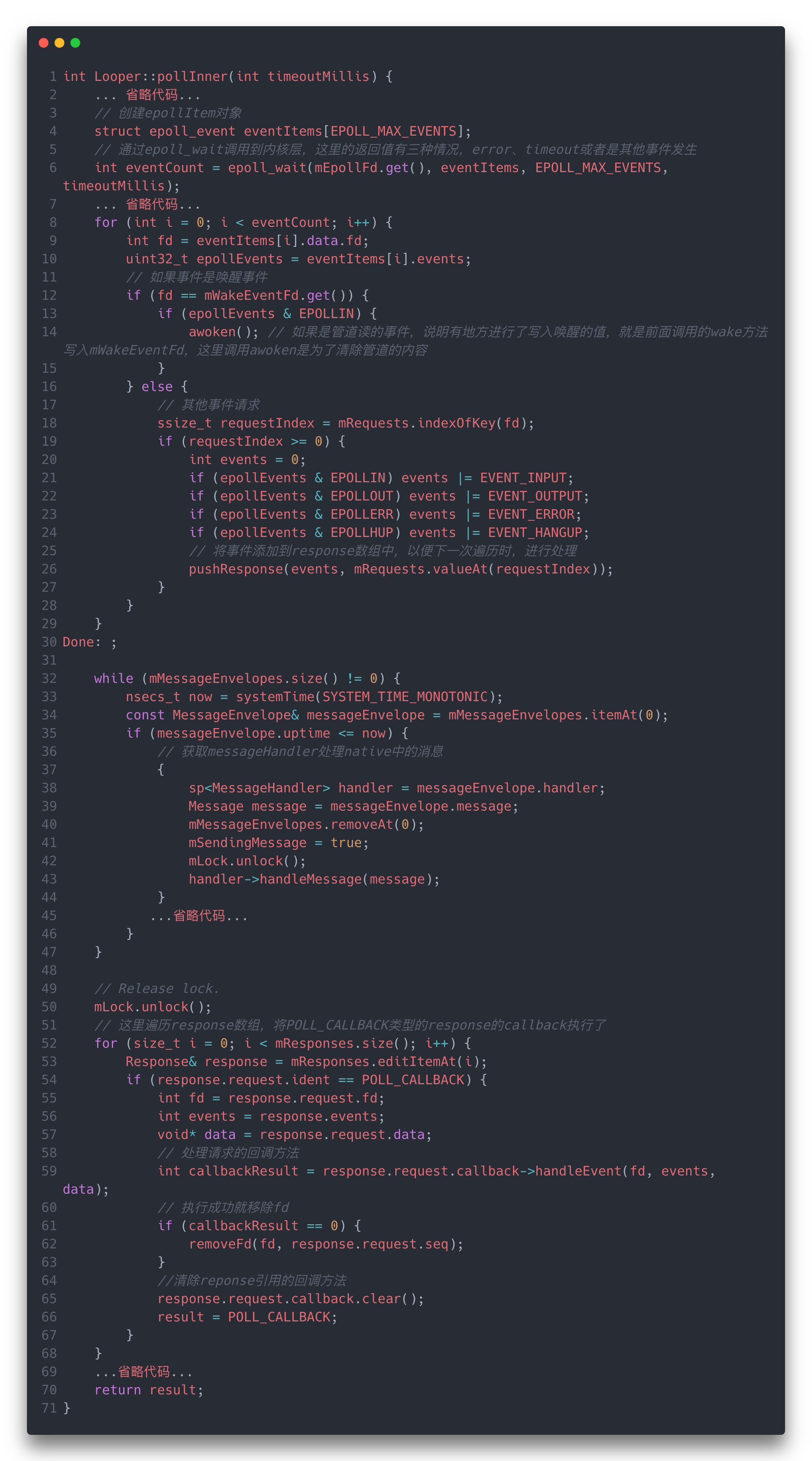
这个方法的逻辑也可以分为三个部分:
- 调用
epoll_wait方法阻塞等待事件的发生,这里可能发生多种事件,如果是唤醒事件,则对应前面新消息的处理或者延迟消息的处理,这个时候会清空管道内的消息,同时执行下面两个部分的事件处理。 - 遍历
mMessageEnvelope中的消息,调用messageHandler来处理消息。 - 执行
mResponse中带callback的事件。
如果后面两种逻辑没有进行事件的处理,那么这个时候pollOnce的死循环就会继续进行到pollInner中,再次执行epoll_wait去等待唤醒事件。
如果后面两种逻辑进行了事件的处理,这个时候Native的死循环就会结束,对Java层来说这一次的阻塞就结束了,Java层的循环逻辑就会继续走。
回到Java这边,当Native的阻塞结束后,就开始处理Java中的消息了。主要是同步和异步消息的处理:
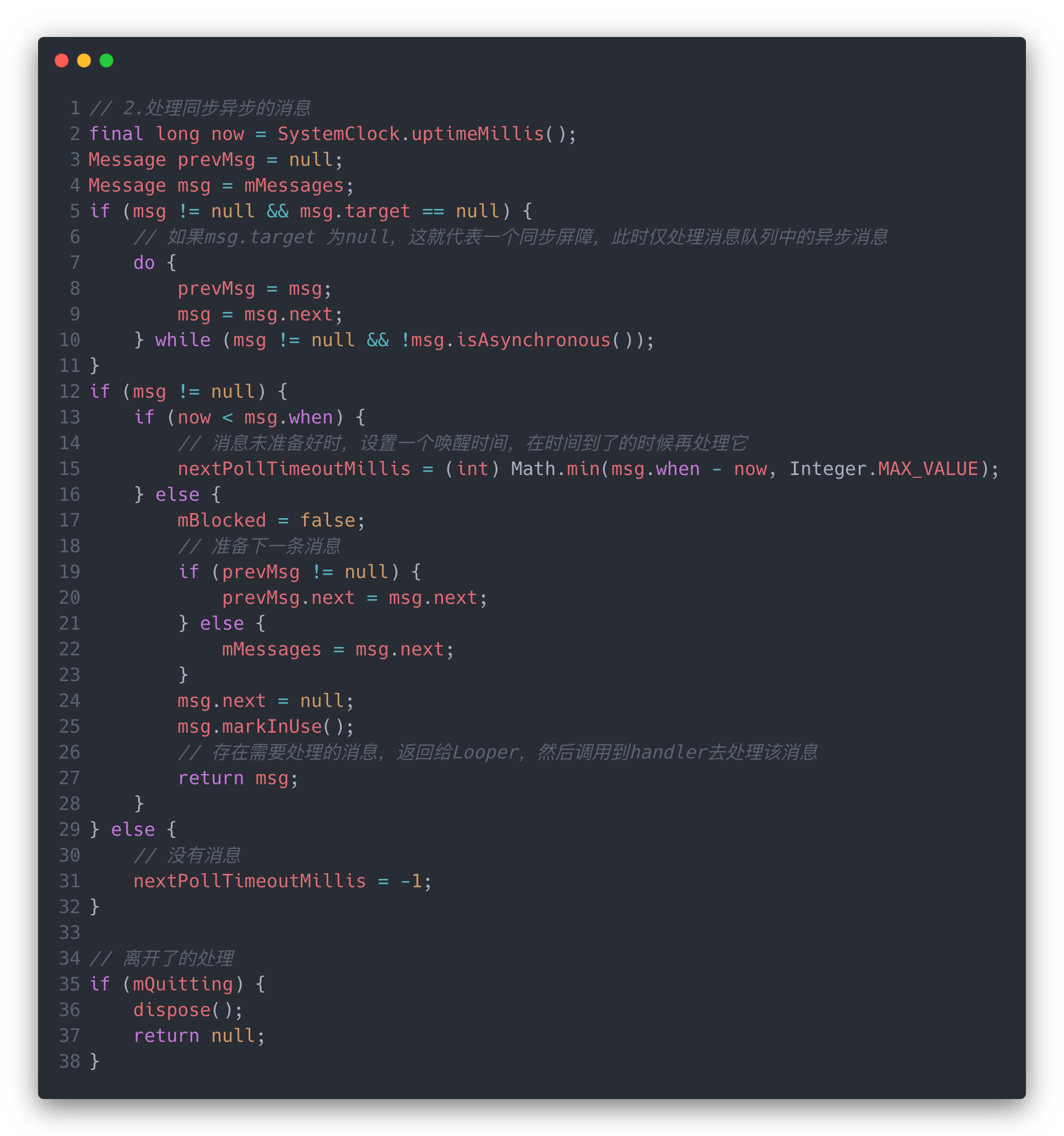
当存在同步屏障时target == null就会仅处理异步消息,否则就按照顺序去处理同步消息。这里会处理消息的时间,要是大于了当前时间,计算出timeout时间,在下一次遍历时会通过nativePollOnce出给Native去阻塞,在时间到了后唤醒自己来处理这条消息。
当然,要是这个时候仍然没有消息可以处理,那我们也可以不让CPU闲着,这个时候会进行idle的任务处理
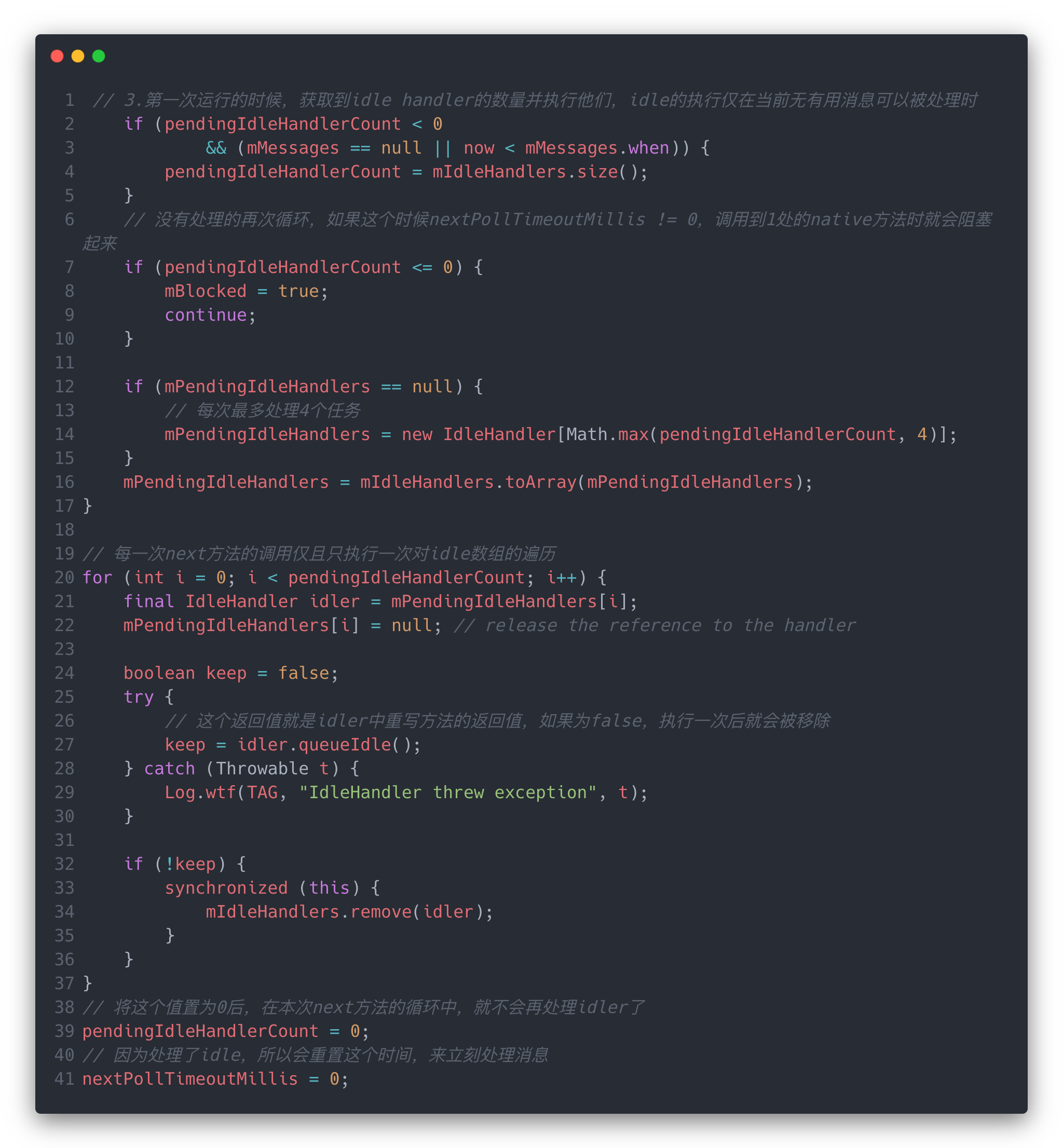
idle的逻辑就比较简单了,从mIdleHandlers中最多取出4个任务来执行,执行一次后本次next()方法的循环就不会再执行idle的任务了,需要等到下一次Loop()方法调用next()的时候才会有可能再去执行idle。这么看其实执行idle的优先级是最低的,因此我们可以把一些不重要的工作放在idle中执行,而且不能影响到正常消息的处理。
处理消息
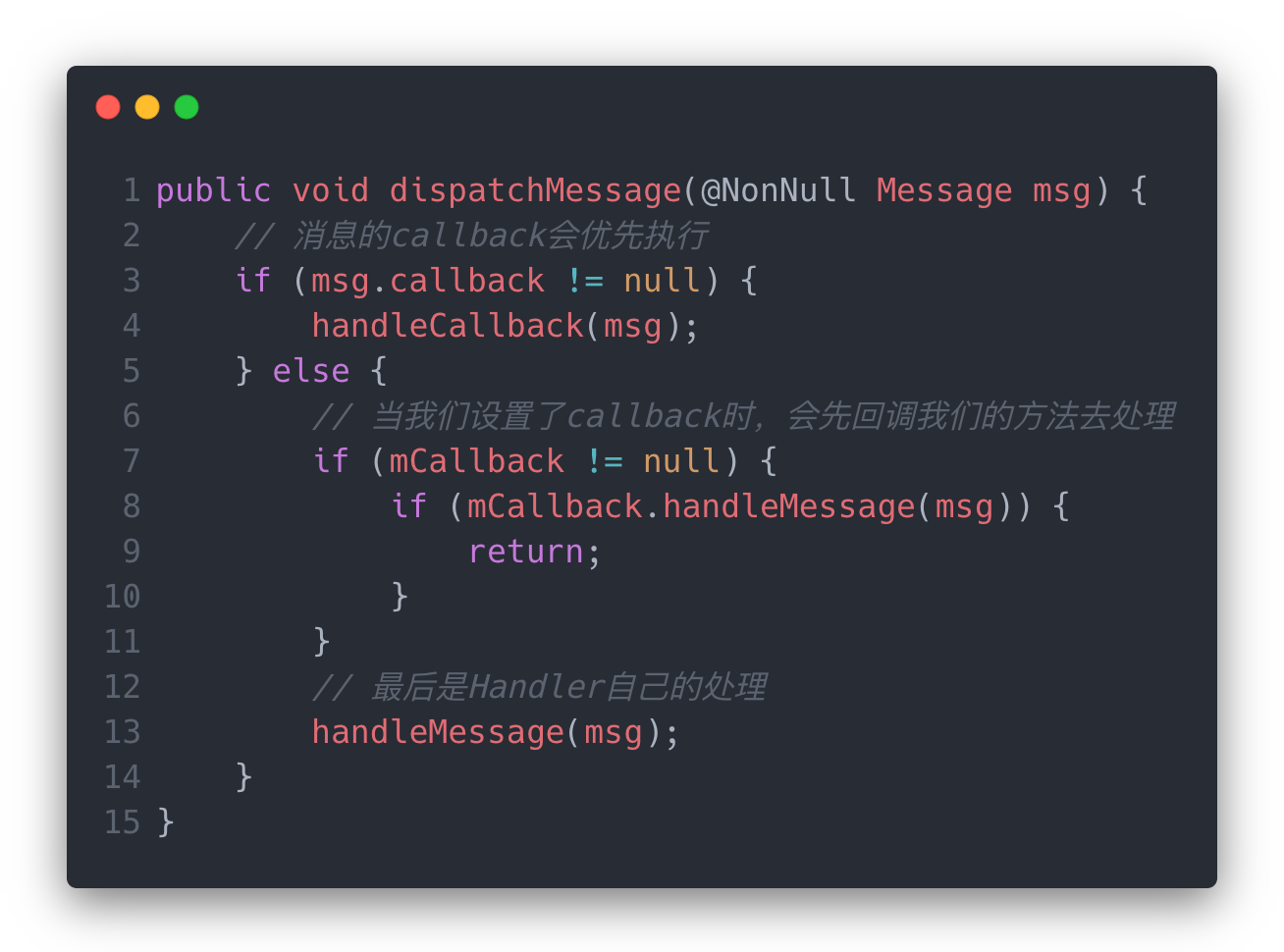
在Looper的处理中,会调用msg.target.dispatchMessage;这个方法中,可以看到有限处理的是消息的callback,也就是我们调用handler.post时发送的那些runnable。接着才是处理handler本身的mCallback,最后才是处理消息。由此可以看出handler在处理的时的优先级,又因为Android中很多通信都是使用的handler,也许解决某些业务的时候可以从这个点入手。
小结一下
扩展思考
关于Handler中的内存泄漏
内存泄漏是个经常讨论的话题,我们这里仅探讨下关于Handler中的内存泄漏问题。无论是以前使用AsyncTask还是现在在主线程中使用Handler进行通信,网上都有说需要注意Handler的内存泄漏问题。Android中的内存资源的重复利用是通过GC机制来保证的,当我们不再使用的内存,会通过GC来回收,不过这个回收的条件是有一定规则的,就是GC需要判断这块内存是否和GCRoot相连接,如果连着,说明不能回收。(为什么这么设计具体可以看《深入理解Java虚拟机》这本书,有非常详细的GC机制介绍)。而发生内存泄漏的原因也是因为本来应该回收的内存仍然和GCRoot连着,能作为GCRoot的对象有好多类型,其中一个就是活跃的线程。这就和Handler的使用对应上了,Handler用于线程间通信,回顾下上面的流程,Handler创建于A线程的ActivityA页面,然后B线程拿到handler实例,发送一个消息,这个时候在A线程的MessageQueue中就存在一条消息,它的target为ActivityA中的handler对象,我们一般使用handler时,都会用匿名内部类实现Callback接口来处理消息,而在Java中,匿名内部类是会隐式的持有外部类的引用的。
将上面的一系列引用串在一起就是,GCRoot(UiThread)->MessageQueue->Message->handler->Callback->ActivityA
当ActivityA在onDestory()之后本来应该会被回收的,但是由于某些情况下,消息没有来得及处理,以至于上面的引用链还存在,这个时候,他就没有办法回收了。
所以有解决方案是,在ondestory()时,调用handler.removeMessages()去清除队列中的消息,这样上面的引用链就断开了,也就解决了内存泄漏问题。
还有之前的方案是使用静态内部类和弱引用,因为静态内部类不会隐式的持有外部类的引用,这样也可以去避免这个问题,不过从上面引用的理解上来说,这种思路不算是一种治本思路。
同步屏障的使用
同步屏障可以保证一些优先级比较高的消息被优先处理。
其实现逻辑主要是将target设置为null,在队列中如果存在这样条件的消息,就代表了存在同步屏障,此时会优先处理异步消息,直到同步屏障移除。
它目前有一个应用的地方是在ViewRootImpl中,当Sync信号到来时,会触发ViewRootImpl中的scheduleTraversals()方法,代码如下

上面是mChoreographer.postCallback方法发布了mTraversalRunnable,这个方法内部层层调用后其实也是将消息插入到主线程的MessageQueue中:

最后在主线程执行绘制,这样能保证绘制相关的消息被优先处理。